linux dev misc
pthread_mutex_t&pthread_cond_t
函数定义:
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex)
int pthread_cond_broadcast(pthread_cond_t *cond)
函数说明:
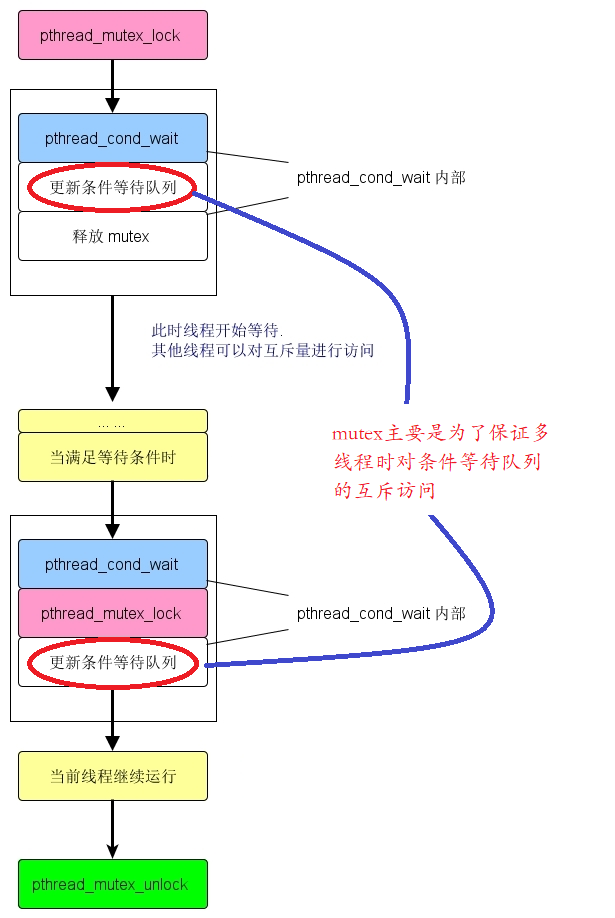
pthread_cond_wait :有两个输入参数,一个是pthread_cond_t,是函数将要等待的信号,另一个是 pthread_mutex_t,一个互斥锁。用于对信号量进行保护,防止多个线程同时对其进行操作。在线程开始等待信号量前,必须由本线程对互斥锁进行锁定,然后pthread_cond_wait会更新条件等待队列,并且释放互斥量,允许其他线程进行访问;当cond 满足条件允许线程继续执行时,wait_cond也会先对mutex 进行锁定,对cond进行处理,然后再允许线程继续运行。所以pthread_cond_wait() 后的pthread_mutex_unlock()还是必要的。
#include <pthread.h>
#include <iostream>
#include <unistd.h>
using namespace std;
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;
static pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
static void* func_1(void* arg){
cout << "func_1 start" << endl;
pthread_mutex_lock(&mtx);
cout << "func_1 lock mtx" << endl;
cout << "func_1 wait cond" << endl;
pthread_cond_wait(&cond, &mtx);
cout << "func_1 unlock mtx" << endl;
pthread_mutex_unlock(&mtx);
cout << "func_1 end" << endl;
sleep(5);
return NULL;
}
static void* func_2(void* arg){
cout << "func_2 start" << endl;
pthread_mutex_lock(&mtx);
cout << "func_2 lock mtx" << endl;
cout << "func_2 wait cond" << endl;
pthread_cond_wait(&cond, &mtx);
cout << "func_2 unlock mtx" << endl;
pthread_mutex_unlock(&mtx);
cout << "func_2 end" << endl;
sleep(5);
return NULL;
}
int main(){
pthread_t tid1, tid2;
cout << "main create thread" << endl;
pthread_create(&tid1, NULL, func_1, NULL);
pthread_create(&tid2, NULL, func_2, NULL);
sleep(3);
cout << "main boradcast signal" << endl;
pthread_cond_broadcast(&cond);
// pthread_cond_signal(&cond);
cout << "main join thread" << endl;
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
cout << "main end" << endl;
return 0;
}
char *a vs char a[]
首先要搞清楚编译程序占用的内存的分区形式:
一、预备知识—程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分:
- 栈区(stack)—由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
- 堆区(heap)—一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
- 全局区(静态区)(static)—全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后由系统释放。
- 字符常量区—常量字符串就是放在这里的。程序结束后由系统释放。
- 程序代码区
这是一个别人写的,非常详细
int a=0; //全局初始化区
char p1; //全局未初始化区
main()
{
int b; //栈
char s[]="abc"; //栈
char p2; //栈
char p3="123456"; //123456\0在常量区,p3在栈上。
static int c = 0; //全局(静态)初始化区
p1 = (char)malloc(10);
p2 = (char)malloc(20); //分配得来得10和20字节的区域就在堆区。
strcpy(p1,"123456"); //123456\0放在常量区,编译器可能会将它与p3指向的"123456"优化成一个地方。
}
首先,我们要知道
- char *a中的a是个指向字符类型的指针,这是一个变量;
- char a[]中的a也是一个指向字符类型的指针,但它是一个常量,常量是不能再给它赋值的,就像比不能写 3=2 这样的代码来给3赋值, 但可以对她指向的内存内容进行修改。
通过阅读我们可以知道,char * a=“abc”和char a[]=”abc”在内存中存放是有差别的,
-
char *a=“abc”中的“abc”是存放于字符常量区的,指针a只是指向了这个地址;
-
char a[]=”abc”中的“abc”其实是放在栈中的,它是字符常量区中“abc”的一份拷贝。
看看下面这段代码你就明白了
#include <stdio.h>
int main()
{
char * a1 = "abc";
char a2[] = "abc";
char * a3 = "abc";
char a4[] = "abc";
printf("char * a:%p\n", a1);//打印a1的值
printf("char a2[]:%p\n",a2);//打印a2的值
printf("char *a3:%p\n", a3);//打印a2的值
printf("char a4[]:%p\n",a4);//打印a2的值
return 0;
}
我在这段代码里声明了两个字符指针变量、两个数组常量指针,代码执行结果如下:
显而易见字符指针变量a 和a3的值是一样的,这说明它们指向同一块内存,这块内存就是上文所说的字符常量区;
字符数组指针a2和a3的值不同且相差4字节,这说明它们指向的内存是不相同的,它们的“abc”其实是对字符常量区中“abc”的一份拷贝,并且数据是存放在栈中的,至于它们的地址相差四个字节,是因为字符数组中在结尾加了一个结束符——‘\0’(也称为NUL)。
至于之前说的“不能直接将一个字符串常量赋值给字符数组”可以这样理解:的确是不能直接赋值,但可以通过复制以后再赋值呀,即把字符串拷贝到栈中,然后给数组指针赋值!代码的话就是:char a[]=“abc”。
我们再来考虑一个问题:能不能修改char *a指向的字符常量区的值呢? 代码如下:
#include <stdio.h>
#include <string.h>
int main()
{
char * a="abc";
*a = 'b';
printf("%c\n",*a);
return 0;
}
我将指针a所指向的第一个字符——‘a’修改为字符‘b’。 结果程序崩溃了
这说明字符常量区的数据是不可以修改的!为什么呢?因为在你的程序中可能有很多个类似于char *a这样的指针变量在使用到了字符常量区的“abc”,如果你在这里通过指针修改了“abc”的值,那么程序中使用“abc”的其他地方就变得不确定了!
其实如果你翻看了《c和指针》你还会发现,在K&R C标准中,这里的修改操作是可以的,因为在该标准中字符串常量是分开存储的,而不是只存储在一个地方。
怎么样,有没有感受到C语言指针的危险和魅力所在?
char a[ ] 的应用场景:
编译器首先判断数组的容量,然后分配一片内存来存储数组的每个元素。如果是字符串赋值方式,则容量是strlen(字符串)+1, 赋值时在尾部加 0
char a[ ] 必须在申明的同时给它赋值, 否则编译器无法知道应该分配多大的内存给该数组
//如下操作会导致 编译错误,编译器不能知道d这个数组的大小
char d[];
char d[] = a;
char a[ ]的两种赋值方式, char a[ ]的优点
char a[] = "dfdsfsdfas"; // char a[]的优点 直接把字符串复制给某个数组,长度+1
char a[] = {'a','a','b','c'}; // 不会有结尾符\0
sizeof(a) 返回的是 a数组容量 * sizeof(a[0])
char *s = “dfdsf” 的应该场景:
把s指向内存的字符串常量区,不能通过s[index] 来修改它, 修改则会crash sizeof(s) 返回的是 sizeof(char *)
#include <stdio.h>
/*-----------------------------------------------------------------------------
* char b[], 遵循 “右左原则 ” 来查看变量的类型, 所以它是一个数组,字符数组
* 它有两种赋值方式
* 1. char b[] = {'1','2','3'};
* 2. char b[] = "123"; 等价与 char b[4] = {'1','2','3', 0};
*------------------------------------------------------------------------------*/
int main(int argc, char *argv[]){
char *a = "12345"; // a 是指针, 指向了字符常量区中"12345"的地址
char b[] = "12345"; // b 是首先是数组,存储的元素是{'1', '2','3','4', '5', 0};
char bb[] = {'1', '2','3','4', '5'}; // bb 是没有结尾符的
char bbb[5] = {'1', '2','3','4', '5'};
int c[] = {1,2,3,4,5};
// char a[ ] 需要在申明的同时给它赋值, 否则编译器无法知道应该分配多大的内存给该数组
// 编译错误,编译器不能知道d这个数组的大小
// char d[];
// char d[] = a;
// 编译错误 把指针赋值数组
// b = a;
//sizeof 返回变量占用的内存大小
// 数组的sizeof 计算是 sizeof(成员)×数目
printf("sizeof(a):%ld sizeof(b):%ld sizeof(bb):%ld sizeof(bbb):%ld sizeof(c):%ld\n", \
sizeof(a), sizeof(b), sizeof(bb), sizeof(bbb), sizeof(c));
b[2] = 'g';
printf("%s():%d\n",__FUNCTION__,__LINE__);
a[2] = 'r'; // 修改字符常量区会导致 crash
printf("%s():%d\n",__FUNCTION__,__LINE__);
a = "dfasdfa";
printf("%s\n",a);
return 0;
}
输出如下:
sizeof(a):8 sizeof(b):6 sizeof(bb):5 sizeof(bbb):5 sizeof(c):20
main():23
Segmentation fault (core dumped)
mmap()
以下是mmap()函数实现的基本过程:
- kernel在当前进程的虚拟地址空间中分配满足条件的虚拟地址块
- 分配vm_area_struct结构来管理该虚拟地址块,并插入到进程的虚拟地址区域链表中
- 通过文件描述符,找到对应设备驱动注册的file_operations,并调用它的mmap函数。
- 在该文件描述符的mmap中,通过调用remap_pfn_range函数来建立页表,并记录文件地址和虚拟地址的映射关系。 此时只是虚拟地址,并没有关联到内存。
- 进程在读写该地址时,触发缺页,从而分配内存,载入文件数据,建立虚拟地址与内存的映射。
fork() 的进程空间
当父进程使用 malloc 分配内存后,这块内存可以被它 fork 的子进程访问。让我详细解释一下。
- 内存分配:
- 父进程使用
malloc分配的内存位于堆(heap)中。这块内存用于存储动态分配的数据,例如字符串、数组等。
- 父进程使用
fork过程:- 当父进程调用
fork创建子进程时,操作系统会复制父进程的地址空间。 - 这包括代码段、数据段、堆和栈。但是,实际的复制并不会立即发生。
- 当父进程调用
- Copy-on-Write(写时复制):
- 写时复制是一种优化策略,用于避免不必要的内存复制。
- 在
fork之后,父子进程共享相同的物理内存页,但这些页被标记为只读。 - 如果父进程或子进程尝试修改这些共享的内存页,操作系统会创建一个副本,使得父子进程之间不会相互影响。
- 因此,父进程和子进程仍然可以访问
fork之前分配的所有数据,包括使用malloc分配的堆内存。
总之,父进程使用 malloc 分配的内存可以被它 fork 的子进程访问,但在修改时会进行复制,以保持数据的独立性¹²。
如果您还有其他问题,欢迎继续提问! 😊
MinGW
MinGW(Minimalist GNU for Windows)是一个用于在Windows平台上编译和链接程序的开发环境,它包含了一个GNU编译器集合(GCC)和一些GNU工具(如Make、GDB等)。MinGW为开发者提供了一套工具,使他们能够在Windows上开发和编译C、C++、Fortran等语言的程序。
MinGW的主要特点
- 跨平台编译器:使用GCC编译器,可以生成Windows可执行文件,支持C、C++、Fortran等多种编程语言。
- 轻量级:相比其他开发环境,如Cygwin,MinGW更为轻量级,不依赖于任何POSIX兼容库。
- 开放源码:MinGW是开源的,任何人都可以自由使用和修改。
- 易于使用:提供了一系列工具和库,使得在Windows上进行开发和调试变得简单。
安装MinGW
以下是在Windows 10上安装MinGW的步骤:
- 下载MinGW安装程序:
访问MinGW官方网站并下载最新的安装程序(通常是mingw-get-setup.exe)。
- 运行安装程序:
运行下载的安装程序。按照提示进行安装,选择你需要的组件。建议至少安装以下组件:
- mingw32-base:基本的MinGW工具,包括GCC编译器。
- mingw32-gcc-g++:G++编译器,用于编译C++代码。
- msys-base:MSYS基本系统,为MinGW提供一个类似UNIX的命令行环境。
- 配置环境变量:
安装完成后,需要将MinGW的bin目录添加到系统的PATH环境变量中,以便在命令行中可以直接使用MinGW的工具。假设MinGW安装在C:\MinGW,将C:\MinGW\bin添加到PATH中。
- 使用MinGW编译代码
安装和配置完成后,你可以使用MinGW编译和运行你的C/C++程序。