DRM子系统
1.DRM总述
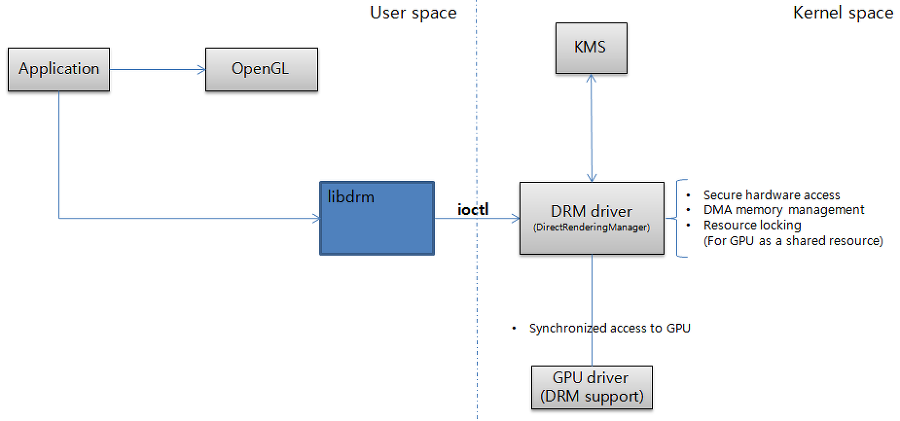
1.1在整个系统中的位置
App角度
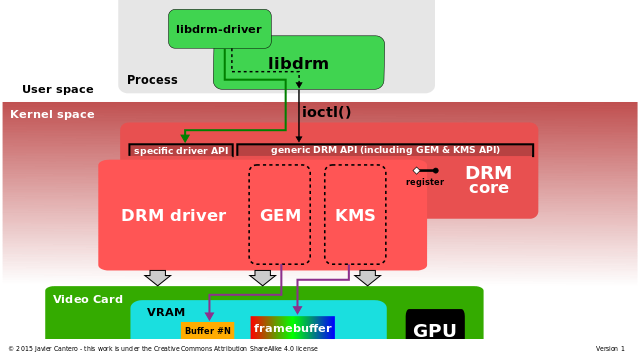
DRM内部
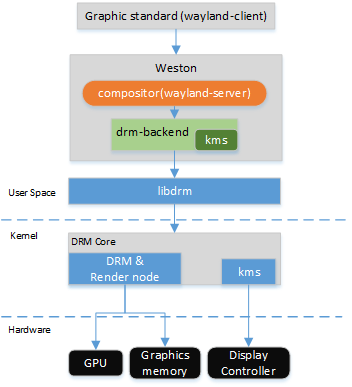
wayland实例
2.图形buffer相关
2.1 dumb buffer
旧时的显卡由一块很小的显存(通常为640x480)加一块数模转换电路(DAC)组成,说白了就是一块 Framebuffer + Display Controller。显卡的功能极其简单,只负责将显存中的图像数据转换成RGB信号发送出去即可,而所有的绘图操作则都交给 CPU 来完成。行业里将这种显卡称为 VGA(Video Graphics Array) Card,它的显存则被称为“Dumb Frame Buffer”。而到了后期,随着显卡技术的不断发展,许多原来由 CPU 干的活,渐渐的都被显卡取代了。从最初支持某些特定绘图指令(如画点、画线)的显卡,到后来支持视频解码的 Video Card,再到现代支持复杂3D渲染指令(如OpenGL)的 GPU 显卡,CPU 绘图的繁重任务彻底得到了解放。与 VGA Card 相比较,行业里将后来显卡的显存称为“Smart Frame Buffer”。
首先从这两种称谓上我们就可以看出,dumb 是 smart 的反义词,因此 dumb 在这里的解释应该是“傻的”或“傻瓜式的”,而不是“哑的”。 dumb buffer 和 smart buffer 的区别就在于,你写到显存里的数据,是可以直接上屏显示的图像内容,还是一堆需要GPU解析的命令和资源数据。
与 dumb buffer 命名类似的还有:
- dumb-terminal:不支持特殊字符的终端,如“清屏”、“粗体”、“彩色字符”等等
- dumb-panel:不带 GRAM 的 panel
- dumb-TV:与 Smart-TV 相反,指以前老式的黑白电视
如今的 IT 领域,dumb一词更多的代表 “功能简单的”、“老式的”、“传统的” 含义
2.1.1超简单DUMB实现
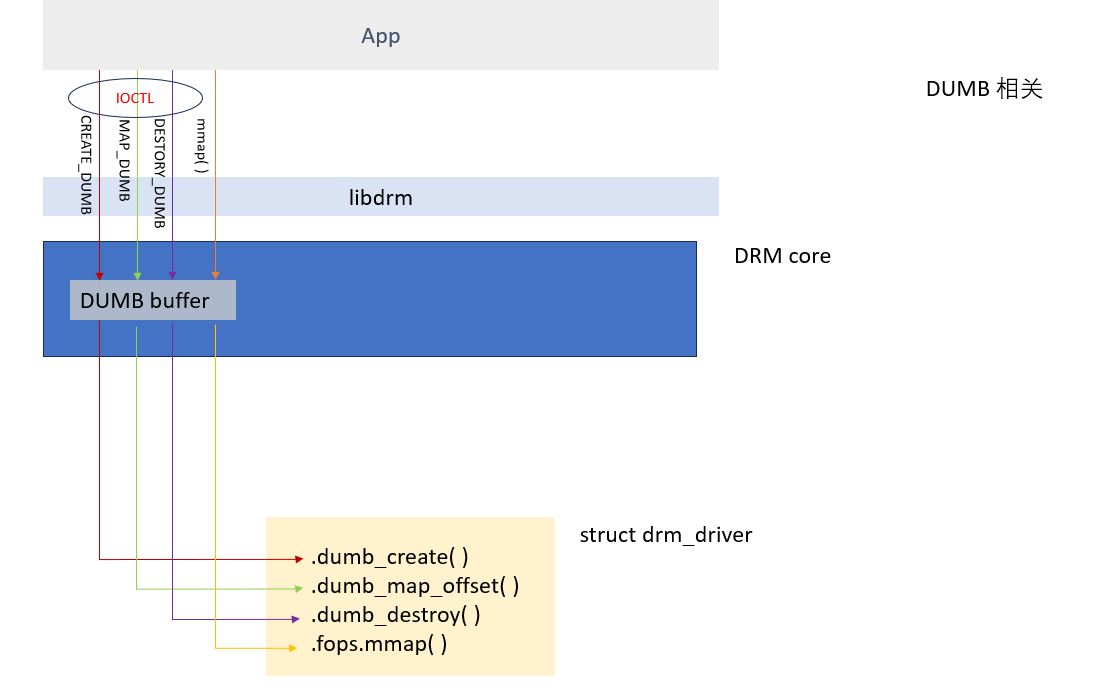
与dumb buffer相关的userspace接口有四个, 下表列出了它们的名字, 作用和对应要实现的函数
| interface | Description | drm driver |
|---|---|---|
| ioctl(fd, DRM_IOCTL_MODE_CREATE_DUMB, …) | 向驱动申请一个dumb buffer,返回一个handle,指向新分配的buffer | .dumb_create() |
| ioctl(fd, DRM_IOCTL_MODE_MAP_DUMB, …) | 为buffer map做准备,传入handle,得到一个offset | .dumb_map_offset() |
| ioctl(fd, DRM_IOCTL_MODE_DESTROY_DUMB, …) | 销毁该dumb buffer | .dumb_destroy() |
| mmap(fd, …) | 传入 buffer对应的offset,映射到进程空间,返回一个用户空间可使用的地址。 | .fops.mmap() |
2.1.1.1 简单应用程序
下面是一个简单的应用程序,演示了dumb buffer的申请,mmap,使用和销毁。
#include <fcntl.h>
#include <stdio.h>
#include <sys/mman.h>
#include <unistd.h>
#include <xf86drm.h>
#define log(fmt, args...) printf("%s():%d " fmt "\n", __func__, __LINE__, ##args)
#define err(fmt, args...) printf("\033[35m%s():%d " fmt "\033[0m\n", __func__, __LINE__, ##args)
static int create_dumb_buffer(int fd, int width, int height){
int ret = 0;
struct drm_mode_create_dumb create = {};
create.width = width;
create.height =height;
create.bpp = 4*8; // byte per pixel
ret = drmIoctl(fd, DRM_IOCTL_MODE_CREATE_DUMB, &create);
if(ret){
err("ret:%d", ret);
return 0;
}
return create.handle;
}
static int get_dumb_buffer_offset(int fd, int handle){
struct drm_mode_map_dumb map = {};
map.handle = handle;
int ret = drmIoctl(fd, DRM_IOCTL_MODE_MAP_DUMB, &map);
if(ret){
err("ret:%d", ret);
return 0;
}
return map.offset;
}
static void* mmap_dumb_buffer(int fd, int size, int offset){
void *addr = NULL;
addr = mmap(0, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, offset);
if(!addr){
err("mmap dumb buffer offset:0x%x failed", offset);
return NULL;
}
return addr;
}
static void destroy_dumb_buffer(int fd, int handle){
struct drm_mode_destroy_dumb destroy = {};
destroy.handle = handle;
int ret = drmIoctl(fd, DRM_IOCTL_MODE_DESTROY_DUMB, &destroy);
if(ret){
err("DRM_IOCTL_MODE_DESTROY_DUMB failed. ret:%d", ret);
return;
}
}
int main(int argc, char **argv){
int fd;
int width = 1024;
int height = 1;
int size = width*height;
fd = open("/dev/dri/card0", O_RDWR | O_CLOEXEC);
if(fd<=0){
err("open dev failed.");
return -1;
}
int handle = create_dumb_buffer(fd, width, height);
log("create dumb buffer, get handle:%d", handle);
int offset = get_dumb_buffer_offset(fd, handle);
log("get dumb buffer offset:0x%x", offset);
void *addr = mmap_dumb_buffer(fd, size, offset);
log("get dumb buffer addr:%p",addr);
//在addr所指向的buffer上进行绘图
memset(addr, 0, width*height);
munmap(addr, size);
destroy_dumb_buffer(fd, handle);
log("destroy dumb buffer");
getchar();
close(fd);
return 0;
}
2.1.1.2 实现简单的驱动
基于kernel 5.15.126, 主要是.dumb_create(), .dumb_map_offset(), .dumb_destroy, fops.mmap()的实现
#include <linux/module.h>
#include <linux/platform_device.h>
#include <drm/drm_drv.h>
#include <drm/drm_file.h>
#include <drm/drm_ioctl.h>
#define DRIVER_NAME "drm dumb driver"
#define DRIVER_DESC "Virtual drm dumb driver"
#define DRIVER_DATE "20191114"
#define DRIVER_MAJOR 1
#define DRIVER_MINOR 0
#define MAX_NUM 10
#define log(fmt, args...) printk("%s():%d " fmt "\n", __func__, __LINE__, ##args)
#define err(fmt, args...) printk("\033[35m%s():%d " fmt "\033[0m\n", __func__, __LINE__, ##args)
struct dumb_device {
struct drm_device drm;
struct platform_device *platform_dev;
};
static struct dumb_device* dumb_device = NULL;
static struct page *pages[MAX_NUM] = {0};
static u32 buffer_size[MAX_NUM] = {0};
static int page_idx = 0;
static int dumb_mmap_impl(struct file* filp, struct vm_area_struct* vma) {
unsigned long pfn_start = 0;
unsigned long size = vma->vm_end - vma->vm_start;
int ret = 0;
int idx = 0;
/*********************************************************************
* vm_pgoff: 也是vm_are_struct的一个字段
* 表示偏移量,它是以page size计数的。 pg表示page计数,off表示偏移
*********************************************************************/
idx = vma->vm_pgoff;
pfn_start = page_to_pfn(pages[idx]);
log("idx:%d phy: 0x%lx, vm_pgoff: 0x%lx, vma->vm_start:0x%lx, size: 0x%lx",
idx, pfn_start << PAGE_SHIFT, vma->vm_pgoff, vma->vm_start, size);
ret = remap_pfn_range(vma, vma->vm_start, pfn_start, size, vma->vm_page_prot);
if (ret)
err("remap_pfn_range failed at [0x%lx 0x%lx]", vma->vm_start, vma->vm_end);
else{
unsigned long virt_start = (unsigned long)page_address(pages[idx]);
log("map 0x%lx to 0x%lx, size: 0x%lx", virt_start, vma->vm_start, size);
}
return 0;
}
static const struct file_operations dumb_driver_fops = {
.owner = THIS_MODULE,
.open = drm_open,
.release = drm_release,
.unlocked_ioctl = drm_ioctl,
.compat_ioctl = drm_compat_ioctl,
.mmap = dumb_mmap_impl,
};
static void dumb_release(struct drm_device* dev) { log(); }
static int dumb_create_impl(struct drm_file *file_priv,
struct drm_device *dev,
struct drm_mode_create_dumb* args) {
u32 size = 0;
log();
if(page_idx>=MAX_NUM){
err("only support alloc %d buffers", MAX_NUM);
return -ENOMEM;
}
size = roundup((args->width * args->height * args->bpp/8), PAGE_SIZE);
// 分配页面
pages[page_idx] = alloc_pages(GFP_KERNEL, get_order(size));
if (!pages[page_idx]) {
err("alloc_pages() failed");
return -ENOMEM;
}
buffer_size[page_idx] = size;
// 赋值返回参数
args->size = size;
args->pitch = args->width * args->bpp/8;
args->handle = page_idx++;
return 0;
}
static int dumb_map_offset_impl(struct drm_file *file_priv,
struct drm_device *dev,
uint32_t handle, uint64_t* offset) {
log("%d", handle);
//根据handle得到一个offset,为了简单,这里直接使用handle
*offset = 0x1000*(u64)handle;
return 0;
}
static int dumb_destroy_impl(struct drm_file *file_priv, struct drm_device *dev, uint32_t handle){
log("handle:%d", handle);
free_pages((unsigned long)page_address(pages[handle]), get_order(buffer_size[handle]));
return 0;
}
static struct drm_driver dumb_driver = {
.fops = &dumb_driver_fops,
.release = dumb_release,
.dumb_create = dumb_create_impl,
.dumb_map_offset = dumb_map_offset_impl,
.dumb_destroy = dumb_destroy_impl,
.name = DRIVER_NAME,
.desc = DRIVER_DESC,
.date = DRIVER_DATE,
.major = DRIVER_MAJOR,
.minor = DRIVER_MINOR,
};
static int __init dumb_drv_init(void) {
int ret;
struct platform_device* pdev = NULL;
log("build time: %s %s", __DATE__, __TIME__);
pdev = platform_device_register_simple(DRIVER_NAME, -1, NULL, 0);
if (IS_ERR(pdev)) return PTR_ERR(pdev);
if (!devres_open_group(&pdev->dev, NULL, GFP_KERNEL)) {
ret = -ENOMEM;
goto out_unregister;
}
// 分配
dumb_device = devm_drm_dev_alloc(&pdev->dev, &dumb_driver, struct dumb_device, drm);
if (IS_ERR(dumb_device)) {
ret = PTR_ERR(dumb_device);
goto out_devres;
}
// 注册
ret = drm_dev_register(&dumb_device->drm, 0);
if (ret) goto out_devres;
dumb_device->platform_dev = pdev;
log("Finish");
return 0;
out_devres:
devres_release_group(&pdev->dev, NULL);
out_unregister:
platform_device_unregister(pdev);
return ret;
}
static void __exit dumb_drv_exit(void) {
struct platform_device *pdev = dumb_device->platform_dev;
log();
drm_dev_unregister(&dumb_device->drm);
devres_release_group(&pdev->dev, NULL);
platform_device_unregister(pdev);
}
module_init(dumb_drv_init);
module_exit(dumb_drv_exit);
MODULE_AUTHOR("kevin");
MODULE_DESCRIPTION(DRIVER_DESC);
MODULE_LICENSE("GPL");
2.1.1.3 它们是如何衔接起来的

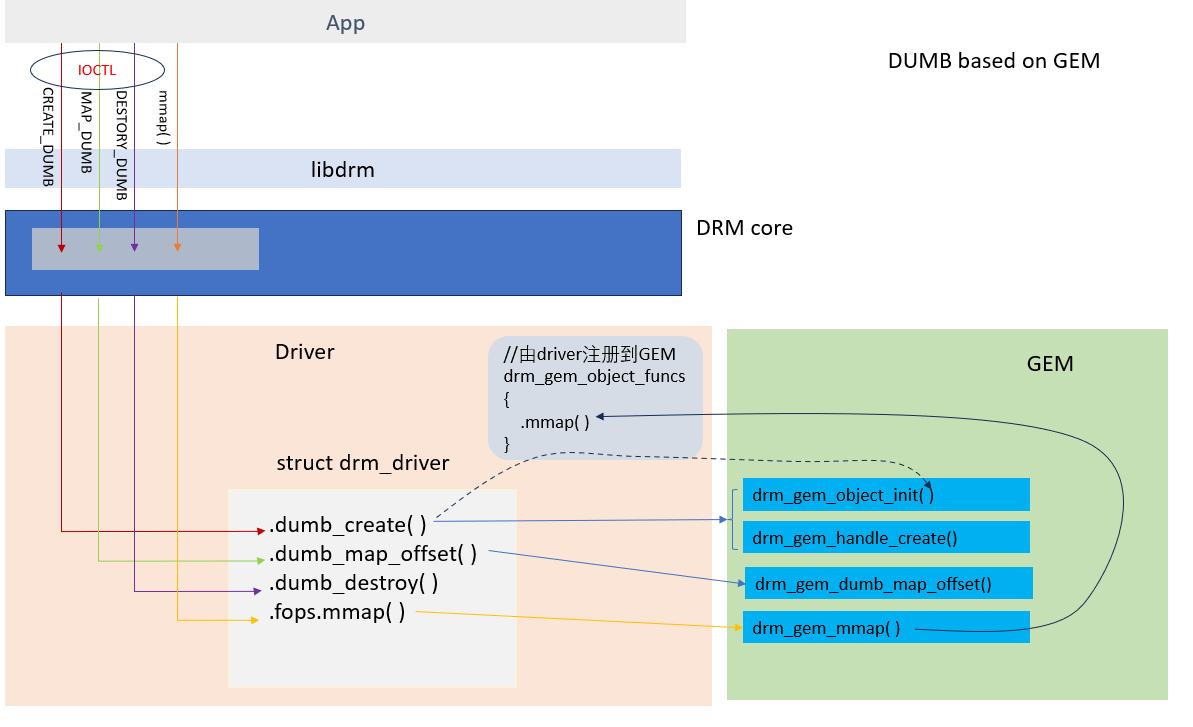
2.1.2 基于GEM的实现
GEM是系统提供的一套实现框架或者帮助工具。在各自实现私有的drm driver时,总有一些内容是相同或相似的,GEM就对这些相同部分进行了总结,抽象,然后实现了它们,供开发者使用。具体实现在drm_gem.c
2.1.2.1 实现代码
下面是基于GEM对上面driver实现的改造。 它利用了GEM 提供的如下函数:
| interface | 功能 |
|---|---|
| drm_gem_object_init() | 初始化一个gem对象 |
| drm_gem_handle_create() | 通过gem对象生成一个handle |
| drm_gem_object_lookup() | 根据handle 找到对应的gem对象 |
| drm_gem_dumb_map_offset() | 通过gem对象生成一个offset |
| drm_gem_mmap() | 对mmap()的支持,如果开发者使用它,就可利用gem mmap的实现部分 |
| struct drm_gem_object_funcs | 使用gem对象时可能调用到一组函数,此处实现了.mmap,对应drm_gem_mmap() |
#include <linux/module.h>
#include <linux/platform_device.h>
#include <drm/drm_gem.h>
#include <drm/drm_drv.h>
#include <drm/drm_file.h>
#include <drm/drm_ioctl.h>
#define DRIVER_NAME "drm dumb gem driver"
#define DRIVER_DESC "Virtual drm dumb driver"
#define DRIVER_DATE "20191116"
#define DRIVER_MAJOR 1
#define DRIVER_MINOR 0
#define log(fmt, args...) printk("%s():%d " fmt "\n", __func__, __LINE__, ##args)
#define err(fmt, args...) printk("\033[35m%s():%d " fmt "\033[0m\n", __func__, __LINE__, ##args)
#define DRM_GEM_OBJECT_TO_DUMB_BUFFER_OBJ(target) \
container_of(target, struct dumb_buffer_object, gem_obj)
struct dumb_device {
struct drm_device drm;
struct platform_device *platform_dev;
};
struct dumb_buffer_object{
struct drm_gem_object gem_obj;
struct page *start_page;
u32 size;
};
static struct dumb_device* dumb_device = NULL;
static int dumb_gem_mmap_impl(struct file* filp, struct vm_area_struct* vma) {
log("call drm_gem_mmap()");
// 利用GEM方法进行mapping,
// 在它里面会调用之前设置好的drm_gem_object_funcs.mmap()
return drm_gem_mmap(filp, vma);
}
static const struct file_operations dumb_driver_fops = {
.owner = THIS_MODULE,
.open = drm_open,
.release = drm_release,
.poll = drm_poll,
.read = drm_read,
.llseek = noop_llseek,
.mmap = dumb_gem_mmap_impl,
.unlocked_ioctl = drm_ioctl,
.compat_ioctl = drm_compat_ioctl,
};
static int dumb_gem_obj_mmap(struct drm_gem_object *gem_obj, struct vm_area_struct *vma){
int ret = 0;
unsigned long pfn_start = 0;
unsigned long size = vma->vm_end - vma->vm_start;
struct dumb_buffer_object *dumb_buffer_obj = NULL;
dumb_buffer_obj = DRM_GEM_OBJECT_TO_DUMB_BUFFER_OBJ(gem_obj);
log("mmaping dumb_buffer_obj:%p", dumb_buffer_obj);
pfn_start = page_to_pfn(dumb_buffer_obj->start_page);
ret = remap_pfn_range(vma, vma->vm_start, pfn_start, size, vma->vm_page_prot);
if (ret){
err("remap_pfn_range failed at [0x%lx 0x%lx]", vma->vm_start, vma->vm_end);
}
return 0;
}
static const struct drm_gem_object_funcs dumb_gem_obj_funcs = {
.open = NULL,
.mmap = dumb_gem_obj_mmap,
//.vm_ops = &dumb_gem_vm_ops, // 赋值到struct vm_area_struct 的vm_ops, 供缺页时调用。
};
static void dumb_release(struct drm_device* dev) { log(); }
static int dumb_create_gem_impl(struct drm_file* file_priv, struct drm_device* dev, struct drm_mode_create_dumb* args) {
u32 size = 0;
int ret = 0;
struct dumb_buffer_object *dumb_buffer_obj;
struct drm_gem_object *gem_obj;
log();
size = ALIGN((args->width * args->height * args->bpp/8), PAGE_SIZE);
//1. 分配buffer_obj
// 可以在此处分配page,也可以在fault时再分配
dumb_buffer_obj = kzalloc(sizeof(*dumb_buffer_obj), GFP_KERNEL);
size = roundup(size, PAGE_SIZE);
log("page_size:%d",size);
// 2. 初始化dumb_buffer_obj内的drm_gem_object
gem_obj = &(dumb_buffer_obj->gem_obj);
gem_obj->funcs = &dumb_gem_obj_funcs; /* 设置该gem object的操作函数 */
drm_gem_object_init(dev, gem_obj, size);
// 3. 利用GEM方法生成一个gem_obj对应的handle
ret = drm_gem_handle_create(file_priv, gem_obj, &args->handle);
if(ret){
log();
}
dumb_buffer_obj->start_page = alloc_pages(GFP_KERNEL, get_order(size));
if (!dumb_buffer_obj->start_page) {
err("alloc_pages() failed");
return -ENOMEM;
}
dumb_buffer_obj->size = size;
// 4. 赋值返回参数
args->size = size;
args->pitch = args->width*args->bpp/8; //TODO: 应计算得到
log("create dumb_buffer_obj:%p success, return handle:%d", dumb_buffer_obj, args->handle);
return 0;
}
static int dumb_map_offset_gem_impl(struct drm_file* file_priv, struct drm_device* dev, uint32_t handle, uint64_t* offset) {
int ret;
log("handle:%d", handle);
// 利用GEM方法得到一个offset
ret =drm_gem_dumb_map_offset(file_priv, dev, handle, offset);
if(ret){
err("drm_gem_dumb_map_offset failed. ret:%d", ret);
}else{
log("get offset:0x%llx from drm_gem_dumb_map_offset()", *offset);
}
return ret;
}
static int dumb_release_gem_impl(struct drm_file *file_priv,
struct drm_device *dev,
u32 handle){
struct drm_gem_object *gem_obj;
struct dumb_buffer_object *dumb_buffer_obj = NULL;
log("");
gem_obj = drm_gem_object_lookup(file_priv, handle);
dumb_buffer_obj = DRM_GEM_OBJECT_TO_DUMB_BUFFER_OBJ(gem_obj);
log("free page:%p",dumb_buffer_obj->start_page);
free_pages((unsigned long)page_address(dumb_buffer_obj->start_page), get_order(dumb_buffer_obj->size));
kfree(dumb_buffer_obj);
return 0;
}
static struct drm_driver dumb_driver = {
.driver_features = DRIVER_GEM,
.fops = &dumb_driver_fops,
.release = dumb_release,
.dumb_create = dumb_create_gem_impl,
.dumb_map_offset = dumb_map_offset_gem_impl,
.dumb_destroy = dumb_release_gem_impl,
.name = DRIVER_NAME,
.desc = DRIVER_DESC,
.date = DRIVER_DATE,
.major = DRIVER_MAJOR,
.minor = DRIVER_MINOR,
};
static int __init dumb_drv_init(void) {
int ret;
struct platform_device* pdev = NULL;
log("build time: %s %s", __DATE__, __TIME__);
pdev = platform_device_register_simple(DRIVER_NAME, -1, NULL, 0);
if (IS_ERR(pdev)) return PTR_ERR(pdev);
if (!devres_open_group(&pdev->dev, NULL, GFP_KERNEL)) {
ret = -ENOMEM;
goto out_unregister;
}
dumb_device = devm_drm_dev_alloc(&pdev->dev, &dumb_driver, struct dumb_device, drm);
if (IS_ERR(dumb_device)) {
ret = PTR_ERR(dumb_device);
goto out_devres;
}
ret = drm_dev_register(&dumb_device->drm, 0);
if (ret) goto out_devres;
dumb_device->platform_dev = pdev;
log("Finish");
return 0;
out_devres:
devres_release_group(&pdev->dev, NULL);
out_unregister:
platform_device_unregister(pdev);
return ret;
}
static void __exit dumb_drv_exit(void) {
struct platform_device *pdev = dumb_device->platform_dev;
log();
drm_dev_unregister(&dumb_device->drm);
devres_release_group(&pdev->dev, NULL);
platform_device_unregister(pdev);
}
module_init(dumb_drv_init);
module_exit(dumb_drv_exit);
MODULE_AUTHOR("kevin");
MODULE_DESCRIPTION(DRIVER_DESC);
MODULE_LICENSE("GPL");
2.1.2.2 流程图

2.2 PRIME
PRIME 在 DRM 驱动中其实是一种buffer共享机制,它是基于 dma-buf 来实现的.
2010年2月9日,NVIDIA 官方发布了一项新的双显卡技术 —— Optimus Technology。该技术主要运用于带双显卡的笔记本(集成显卡+独立显卡),可以根据当前集成显卡的工作负载,自动的将一部分图形任务交给独立显卡去处理,以此来达到功耗和性能的最佳平衡。举例来说,一个带 Intel 集成显卡和 NVIDIA 独立显卡的笔记本,通常将集成显卡做为默认显卡,且充当了 Display Controller 的角色。当用户使用办公软件时,由于需要渲染的任务量不多,此时直接由 Intel 集成显卡来完成。而当用户玩3D游戏时,由于图形渲染的负载较重,此时系统会将部分或全部的任务交给 NVIDIA 独立显卡去处理,等处理完后再将结果送回给集成显卡做最后的合成显示。而这整个过程都是由软硬件自动完成的,中间无需人为干预,用户体验十分流畅。只可惜,该技术只能用在 Windows 系统上,Linux 系统不支持。
当时的 Linux 开源社区,Dave Airlie (RedHat Graphics 工程师,DRM 社区 maintainer)在业余时间里研究起 Optimus 技术,并琢磨着怎样在 Linux 平台上实现类似的功能。结果不到2周时间,他就做出了该方案的原型设计,并在自己的笔记本上(Intel集成显卡+ATI独立显卡)实现了该功能的验证。
他将这项技术命名为“PRIME”。 命名为PRIME 主要是映射Optimus
Optimus Prime 就是变形金刚 擎天柱的名字! NVIDIA 当初给他们 Optimus 技术命名的精妙之处:擎天柱本身所具有的变形能力,形象的表达了 Optimus 这项技术可以在功耗和性能之间来回自由变换。 Dave 将他这项 Linux 下的技术命名为 “PRIME”,其实是很巧妙的玩了一把文字游戏,隐晦的告诉大家:DRM Prime 技术就是用来对标 NVIDIA Optimus 技术的。
2.2.1 PRIME的基本实现
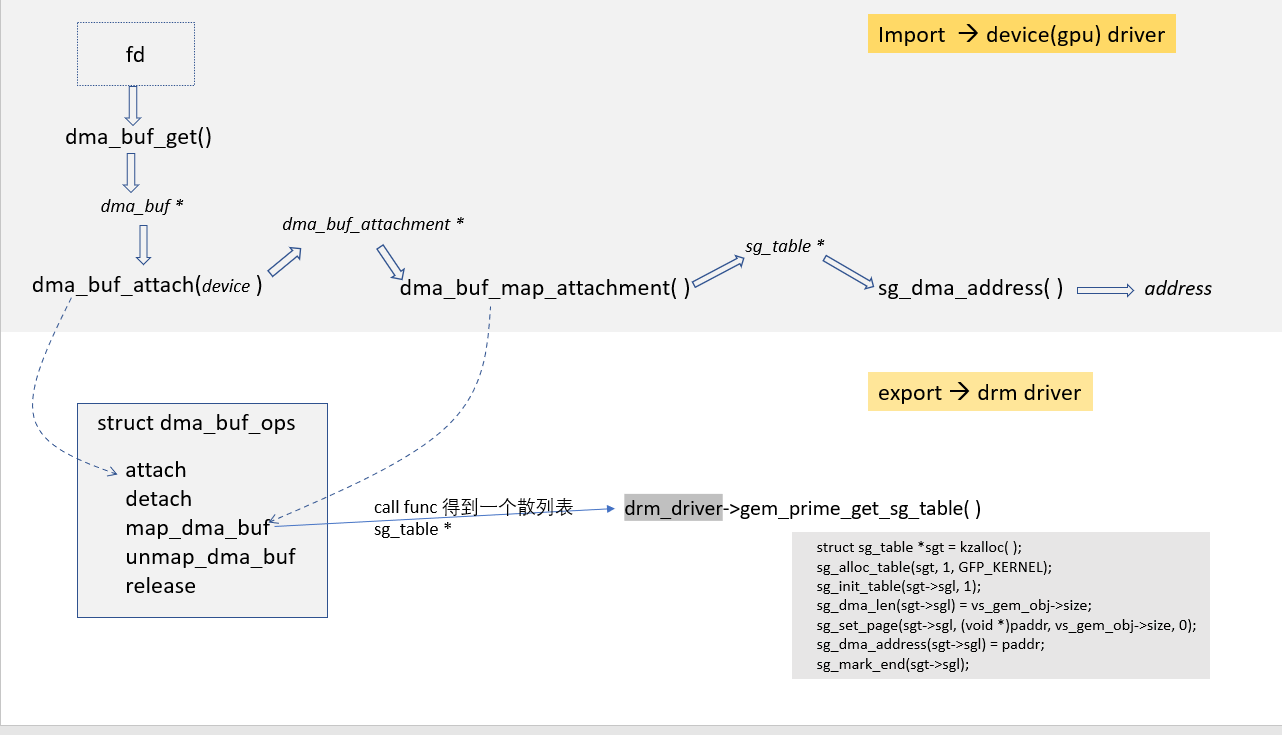
为了实现设备间的buffer共享,需要有一套机制来导出、导入buffer。提供buffer的驱动负责导出buffer,使用buffer的设备导入buffer。 DMA_BUF已经提供了这样一套机制。 在DRM的实现中就使用了这套机制,具体是通过借助dmabuf fd来完成的。 导出buffer的驱动对外提供一个fd,来代表一个buffer, 而要使用这个buffer的其他设备驱动就通过这个fd导入buffer,从而访问该buffer。 在DRM中我们需要实现一定的DMA_BUF接口来支持buffer的导出、导入。
下图是一个在不同设备驱动之间导入、导出dma_buf的简单示意图
2.2.1.1 export驱动实现
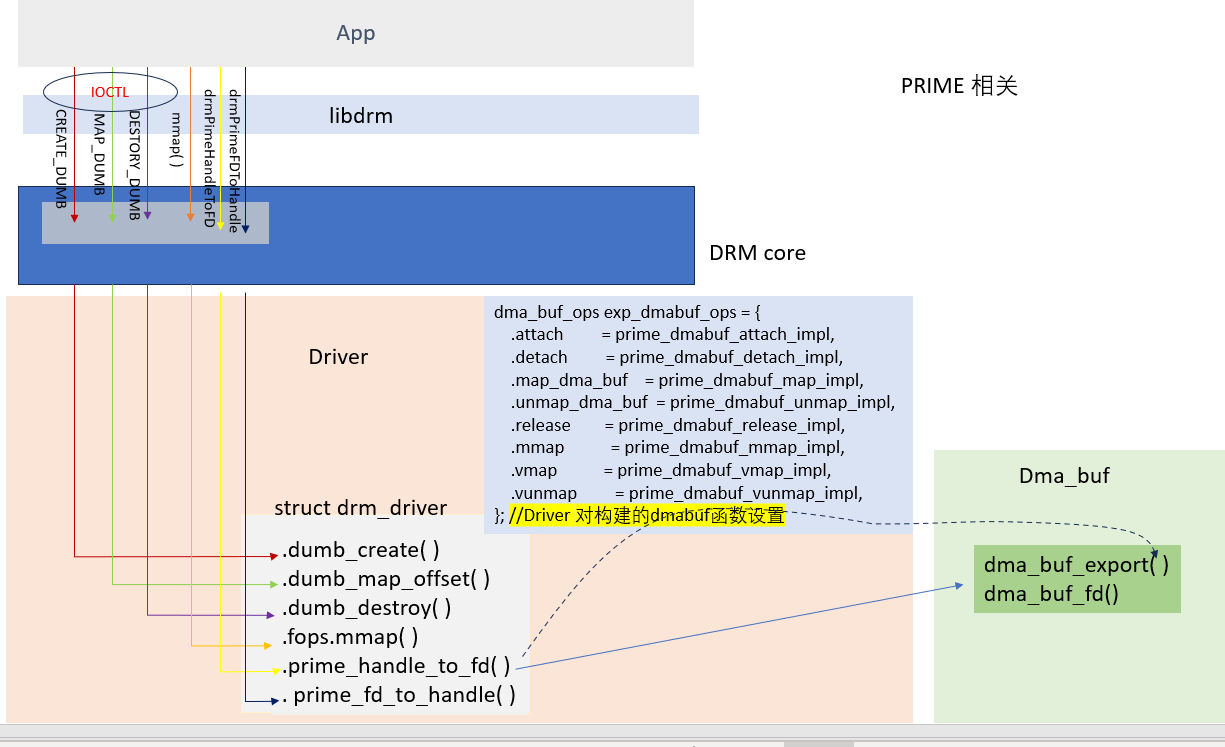
在驱动的实现中主要添加 .prime_handle_to_fd 和 .prime_fd_to_handle_impl的实现。
| interface | 实现功能 |
|---|---|
| prime_handle_to_fd | 需要实现buffer handle 到dmabuf fd的转换 |
| prime_fd_to_handle_impl | 需要实现dmabuf fd 到buffer handle的转换 |
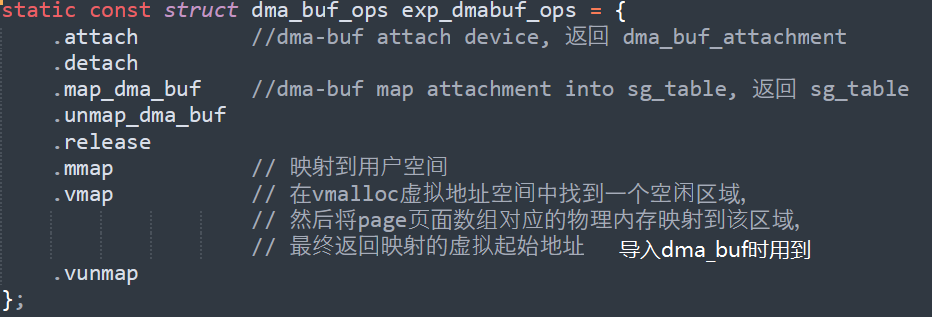
下面是支持buffer导出的简单实现. 在前面code的基础上添加了对dma-buf export的支持,主要是对struct dma_buf_ops的实现。
结构dma_buf_ops
struct dma_buf_ops结构如下:

#include <linux/module.h>
#include <linux/platform_device.h>
#include <linux/slab.h>
#include <linux/dma-buf.h>
#include <drm/drm_drv.h>
#include <drm/drm_file.h>
#include <drm/drm_ioctl.h>
#define DRIVER_NAME "drm prime driver"
#define DRIVER_DESC "test drm prime driver"
#define DRIVER_DATE "20191124"
#define DRIVER_MAJOR 1
#define DRIVER_MINOR 0
#define log(fmt, args...) printk("%s():%d " fmt "\n", __func__, __LINE__, ##args)
#define err(fmt, args...) printk("\033[35m%s():%d " fmt "\033[0m\n", __func__, __LINE__, ##args)
struct dumb_device {
struct drm_device drm;
struct platform_device* platform_dev;
};
#define MAX_NUM 10
static struct dumb_device* dumb_device = NULL;
static struct page* pages[MAX_NUM] = {0};
static u32 buffer_size[MAX_NUM] = {0};
static int page_idx = 0;
static int prime_dmabuf_attach_impl(struct dma_buf* dmabuf, struct dma_buf_attachment* attachment) {
log("attach dmabuf to device, return attachment");
return 0;
}
static void prime_dmabuf_detach_impl(struct dma_buf* dmabuf, struct dma_buf_attachment* attachment) { log("detach dmabuf"); }
static struct sg_table* prime_dmabuf_map_impl(struct dma_buf_attachment* attachment, enum dma_data_direction dir) {
struct page* page = attachment->dmabuf->priv;
struct sg_table* table;
int err;
log("page:%p", page);
table = kmalloc(sizeof(*table), GFP_KERNEL);
if (!table) {
log();
return ERR_PTR(-ENOMEM);
}
// 生成散列表并赋值
err = sg_alloc_table(table, 1, GFP_KERNEL);
if (err) {
log();
kfree(table);
return ERR_PTR(err);
}
sg_set_page(table->sgl, page, PAGE_SIZE, 0);
sg_dma_address(table->sgl) = dma_map_page(&(dumb_device->platform_dev->dev), page, 0, PAGE_SIZE, dir);
log("map attachment into sg_table and return sg_table");
return table;
}
static void prime_dmabuf_unmap_impl(struct dma_buf_attachment* attachment, struct sg_table* table, enum dma_data_direction dir) {
log();
dma_unmap_page(attachment->dev, sg_dma_address(table->sgl), PAGE_SIZE, dir);
sg_free_table(table);
kfree(table);
}
static void prime_dmabuf_release_impl(struct dma_buf* dma_buf) {
struct page* page = dma_buf->priv;
log("put_page:%p", page);
put_page(page);
}
static int prime_dmabuf_vmap_impl(struct dma_buf* dma_buf, struct dma_buf_map* map) {
void* vaddr = NULL;
struct page* page = dma_buf->priv;
vaddr = vmap(&page, 1, 0, PAGE_KERNEL);
dma_buf_map_set_vaddr(map, vaddr);
log("mapping page:%p, get virtual addr:%p", page, vaddr);
return 0;
}
static void prime_dmabuf_vunmap_impl(struct dma_buf* dma_buf, struct dma_buf_map* map) {
log("unmapping addr:%p", map->vaddr);
vunmap(map->vaddr);
}
static int prime_dmabuf_mmap_impl(struct dma_buf* dma_buf, struct vm_area_struct* vma) {
struct page* page = dma_buf->priv;
log();
return remap_pfn_range(vma, vma->vm_start, page_to_pfn(page), PAGE_SIZE, vma->vm_page_prot);
}
static const struct dma_buf_ops exp_dmabuf_ops = {
.attach = prime_dmabuf_attach_impl,
.detach = prime_dmabuf_detach_impl,
.map_dma_buf = prime_dmabuf_map_impl,
.unmap_dma_buf = prime_dmabuf_unmap_impl,
.release = prime_dmabuf_release_impl,
.mmap = prime_dmabuf_mmap_impl,
.vmap = prime_dmabuf_vmap_impl,
.vunmap = prime_dmabuf_vunmap_impl,
};
static int prime_handle_to_fd_impl(struct drm_device* dev, struct drm_file* file_priv, uint32_t handle, uint32_t flags,
int* prime_fd) {
DEFINE_DMA_BUF_EXPORT_INFO(exp_info);
struct dma_buf* dmabuf;
log("dma_buf -> page:%p", pages[handle]);
exp_info.ops = &exp_dmabuf_ops;
exp_info.size = buffer_size[handle];
exp_info.flags= O_CLOEXEC;
exp_info.priv = pages[handle]; // buffer和dmabuf建立关联
// 构建一个dma_buf
dmabuf = dma_buf_export(&exp_info);
if (IS_ERR(dmabuf)) {
log();
return -1;
}
// 为该dma_buf生成fd
*prime_fd = dma_buf_fd(dmabuf, O_CLOEXEC);
if (prime_fd <= 0) {
log();
return -1;
}
return 0;
}
static int prime_fd_to_handle_impl(struct drm_device* dev, struct drm_file* file_priv, int prime_fd, uint32_t* handle) {
struct dma_buf* dma_buf;
struct page* page = NULL;
int idx = 0;
log();
dma_buf = dma_buf_get(prime_fd);
page = dma_buf->priv;
if (dma_buf->ops == &exp_dmabuf_ops) {
for (idx = 0; idx < MAX_NUM; idx++) {
if (pages[idx] == page) {
break;
}
}
*handle = idx;
log("return handle:%d", *handle);
} else {
log("doesn't support");
return -1;
}
dma_buf_put(dma_buf);
return 0;
}
static const struct file_operations dumb_driver_fops = {
.owner = THIS_MODULE,
.open = drm_open,
.release = drm_release,
.unlocked_ioctl = drm_ioctl,
.compat_ioctl = drm_compat_ioctl,
};
static void dumb_release(struct drm_device* dev) { log(); }
static int dumb_create_impl(struct drm_file *file_priv,
struct drm_device *dev,
struct drm_mode_create_dumb* args) {
u32 size = 0;
log();
if(page_idx>=MAX_NUM){
err("only support alloc %d buffers", MAX_NUM);
return -ENOMEM;
}
size = roundup((args->width * args->height * args->bpp/8), PAGE_SIZE);
// 分配页面
pages[page_idx] = alloc_pages(GFP_KERNEL, get_order(size));
if (!pages[page_idx]) {
err("alloc_pages() failed");
return -ENOMEM;
}
buffer_size[page_idx] = size;
// 赋值返回参数
args->size = size;
args->pitch = args->width * args->bpp/8;
args->handle = page_idx++;
return 0;
}
static int dumb_destroy_impl(struct drm_file *file_priv, struct drm_device *dev, uint32_t handle){
log("handle:%d", handle);
//__free_pages(pages[handle], get_order(dumb_buffer_size[handle]));
free_pages((unsigned long)page_address(pages[handle]), get_order(buffer_size[handle]));
return 0;
}
static struct drm_driver dumb_driver = {
.release = dumb_release,
.fops = &dumb_driver_fops,
.dumb_create = dumb_create_impl,
.dumb_destroy = dumb_destroy_impl,
.prime_handle_to_fd = prime_handle_to_fd_impl,
.prime_fd_to_handle = prime_fd_to_handle_impl, //其他驱动分配的dma_buf导入到DRM系统
.name = DRIVER_NAME,
.desc = DRIVER_DESC,
.date = DRIVER_DATE,
.major = DRIVER_MAJOR,
.minor = DRIVER_MINOR,
};
static int __init dumb_drv_init(void) {
int ret;
struct platform_device* pdev = NULL;
log("build time: %s %s", __DATE__, __TIME__);
pdev = platform_device_register_simple(DRIVER_NAME, -1, NULL, 0);
if (IS_ERR(pdev)) return PTR_ERR(pdev);
if (!devres_open_group(&pdev->dev, NULL, GFP_KERNEL)) {
ret = -ENOMEM;
goto out_unregister;
}
// 分配
dumb_device = devm_drm_dev_alloc(&pdev->dev, &dumb_driver, struct dumb_device, drm);
if (IS_ERR(dumb_device)) {
ret = PTR_ERR(dumb_device);
goto out_devres;
}
// 注册
ret = drm_dev_register(&dumb_device->drm, 0);
if (ret) goto out_devres;
dumb_device->platform_dev = pdev;
log("Finish");
return 0;
out_devres:
devres_release_group(&pdev->dev, NULL);
out_unregister:
platform_device_unregister(pdev);
return ret;
}
static void __exit dumb_drv_exit(void) {
struct platform_device *pdev = dumb_device->platform_dev;
log();
drm_dev_unregister(&dumb_device->drm);
devres_release_group(&pdev->dev, NULL);
platform_device_unregister(pdev);
}
module_init(dumb_drv_init);
module_exit(dumb_drv_exit);
MODULE_AUTHOR("kevin");
MODULE_DESCRIPTION(DRIVER_DESC);
MODULE_LICENSE("GPL");
2.2.1.1 import驱动实现
import dmabuf 的驱动部分实现较为简单,主要是对下列函数的调用,这些函数正好和上面struct dma_buf_ops的实现相对应。
| function | 功能 |
|---|---|
| dma_buf_get | 由fd得到对应的struct dma_buf |
| dma_buf_attach | attach dmabuf 到一个设备,得到一个 dma_buf_attachment |
| dma_buf_map_attachment | 把一个dmabuf映射到一个设备的地址空间 |
| dma_buf_unmap_attachment | 取消dmabuf在设备地址空间的映射 |
| dma_buf_detach | 取消与设备的关联 |
#include <linux/dma-buf.h>
#include <linux/module.h>
#include <linux/miscdevice.h>
#include <linux/slab.h>
#define log(fmt, args...) printk("%s():%d " fmt "\n", __func__, __LINE__, ##args)
static int test_dma_buf(struct dma_buf* dma_buf) {
struct dma_buf_attachment* attachment;
struct sg_table* table;
struct device* dev;
unsigned int reg_addr, reg_size;
struct scatterlist* sg;
struct page* page;
int i = 0;
if (!dma_buf) {
log();
return -EINVAL;
}
dev = kzalloc(sizeof(*dev), GFP_KERNEL);
if (!dev) {
log();
return -ENOMEM;
}
dev_set_name(dev, "importer");
attachment = dma_buf_attach(dma_buf, dev);
if (IS_ERR(attachment)) {
pr_err("dma_buf_attach() failed\n");
return PTR_ERR(attachment);
}
log("call dma_buf_map_attachment to get sg_table");
table = dma_buf_map_attachment(attachment, DMA_BIDIRECTIONAL);
if (IS_ERR(table)) {
pr_err("dma_buf_map_attachment() failed\n");
dma_buf_detach(dma_buf, attachment);
return PTR_ERR(table);
}
log("table->nents:%d", table->nents);
sg = table->sgl;
for (i = 0; i < table->nents; i++) {
reg_addr = sg_dma_address(sg);
reg_size = sg_dma_len(sg);
page = sg_page(sg);
log("addr = 0x%08x, size = 0x%08x %p %p\n", reg_addr, reg_size, page, page_address(page));
sg = sg_next(sg);
}
// do something on dma-buf
log("unmap and detach dma_buf");
dma_buf_unmap_attachment(attachment, table, DMA_BIDIRECTIONAL);
dma_buf_detach(dma_buf, attachment);
return 0;
}
static long importer_ioctl(struct file* filp, unsigned int cmd, unsigned long arg) {
int fd;
struct dma_buf* dma_buf;
if (copy_from_user(&fd, (void __user*)arg, sizeof(int))) {
log("copy_from_user() failed");
return -EFAULT;
}
dma_buf = dma_buf_get(fd);
log("get dma_buf:%p by fd:%d", dma_buf, fd);
if (IS_ERR(dma_buf)) {
log();
return PTR_ERR(dma_buf);
}
test_dma_buf(dma_buf);
return 0;
}
static struct file_operations importer_fops = {
.owner = THIS_MODULE,
.unlocked_ioctl = importer_ioctl,
};
static struct miscdevice mdev = {
.minor = MISC_DYNAMIC_MINOR,
.name = "importer",
.fops = &importer_fops,
};
static int __init importer_init(void) {
log();
return misc_register(&mdev);
}
static void __exit importer_exit(void) {
log();
misc_deregister(&mdev);
}
module_init(importer_init);
module_exit(importer_exit);
MODULE_LICENSE("GPL v2");
2.2.1.1 进程间分享fd
如果要不同设备中共享buffer,就需要导入dmabuf到不同的设备中,这就涉及到一个fd共享的问题。我们知道fd是和进程相关的,每个进程都有它自己的文件描述符表,不同进程的fd表是不同的。所以不能把一个进程的fd直接传递给另一个进程中使用,需要通过一定的方法来共享fd,也就是fd的跨进程传递。 这个方法就是UNIX域的socket接口。 代码如下:
发送方代码:
#define SHARE_DMABUF_PATH "./share_dmabuf_file"
static void send_fd(int fd)
{
int ret = 0;
char c = 0;
struct iovec iov[1];
iov[0].iov_base = &c;
iov[0].iov_len = 1;
int sockfd = 0;
struct sockaddr_un addr;
bzero(&addr, sizeof(addr));
addr.sun_family = AF_UNIX;
strcpy(addr.sun_path, SHARE_DMABUF_PATH);
sockfd = socket(AF_UNIX, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("socket error");
exit(-1);
}
ret = connect(sockfd, (struct sockaddr *)&addr, sizeof(addr));
if(ret <0){
perror("connect() failed");
exit(0);
}
int cmsgsize = CMSG_LEN(sizeof(int));
struct cmsghdr* cmptr = (struct cmsghdr*)malloc(cmsgsize);
if(cmptr == NULL){
err_exit();
}
cmptr->cmsg_level = SOL_SOCKET;
cmptr->cmsg_type = SCM_RIGHTS;
cmptr->cmsg_len = cmsgsize;
struct msghdr msg;
msg.msg_iov = iov;
msg.msg_iovlen = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
msg.msg_control = cmptr;
msg.msg_controllen = cmsgsize;
*(int *)CMSG_DATA(cmptr) = fd;
ret = sendmsg(sockfd, &msg, 0);
if (ret == -1){
perror("sendmsg() failed.");
err_exit();
}
free(cmptr);
close(sockfd);
}
接收方代码
static int recv_fd(int sock)
{
struct cmsghdr* pcmsg = NULL;
union {
struct cmsghdr cm;
char control[CMSG_SPACE(sizeof(int))];
} control_un;
char buf;
struct iovec iov[1];
iov[0].iov_base = &buf;
iov[0].iov_len = sizeof(buf);
struct msghdr msg;
msg.msg_iov = iov;
msg.msg_iovlen = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
msg.msg_control = control_un.control;
msg.msg_controllen = sizeof(control_un.control);;
int ret = recvmsg(sock, &msg, 0);
if (ret == -1) {
printf("\033[31m%s:%d sock:%d err:%m \033[0m\n\n",__func__,__LINE__, sock);
exit(1);
}
pcmsg = CMSG_FIRSTHDR(&msg);
int fd = *(int *)CMSG_DATA(pcmsg);
return fd;
}
static int recv_prime_fd_from_socket(void){
int sockfd = 0;
struct sockaddr_un addr;
unlink(SHARE_DMABUF_PATH);
addr.sun_family = AF_UNIX;
strcpy(addr.sun_path, SHARE_DMABUF_PATH);
int prime_fd;
int clientfd;
struct sockaddr cliaddr;
socklen_t clilen;
unsigned int len = strlen(addr.sun_path) + sizeof(addr.sun_family);
sockfd = socket(AF_UNIX, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("socket error");
exit(-1);
}
if (bind(sockfd, (struct sockaddr*)&addr, len) < 0) {
perror("bind error");
close(sockfd);
exit(-1);
}
listen(sockfd, 2);
clientfd = accept(sockfd, (struct sockaddr *)&cliaddr, &clilen);
if(clientfd<=0){
log("clientfd:%d %m", clientfd);
exit(-1);
}
prime_fd = recv_fd(clientfd);
log("Recv prime_fd: %d", prime_fd);
return prime_fd;
}
2.2.1.2 测试程序
基于上述进程间分享fd的方法,结合PRIME export和import驱动实现,可以写出如下测试PRIME的code
导出 prime 部分
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <xf86drm.h>
#include <sys/socket.h>
#include <sys/un.h>
#define SHARE_DMABUF_PATH "./tt"
#define log(fmt, args...) printf("%s():%d " fmt "\n", __func__, __LINE__, ##args)
#define err_return(fmt, args...) do{ \
printf("%s():%d " fmt "\n", __func__, __LINE__, ##args); \
return -1;\
}while(0)
#define err_exit(fmt, args...) do{ \
printf("%s():%d " fmt "\n", __func__, __LINE__, ##args); \
exit(1);\
}while(0)
struct buffer_object {
uint32_t width;
uint32_t height;
uint32_t pitch;
uint32_t handle;
uint32_t size;
int prime_fd;
};
struct buffer_object buf;
static int create_dumb_get_prime_fd(int fd, struct buffer_object *bo){
int ret = 0;
struct drm_mode_create_dumb create = {};
create.width = bo->width;
create.height = bo->height;
create.bpp = 4*8; //ARGB
ret = drmIoctl(fd, DRM_IOCTL_MODE_CREATE_DUMB, &create);
if(ret){
err_return("drmIoctl(DRM_IOCTL_MODE_CREATE_DUMB) failed");
}
ret = drmPrimeHandleToFD(fd, create.handle, DRM_CLOEXEC, &bo->prime_fd);
if(ret){
err_return("drmPrimeHandleToFD() failed");
}
bo->handle = create.handle;
log("get handle:%d prime fd:%d", create.handle, bo->prime_fd);
return 0;
}
static void destroy_fd(int fd, struct buffer_object *bo){
int ret = 0;
uint32_t handle = 0;
struct drm_mode_destroy_dumb destroy = {};
ret = drmPrimeFDToHandle(fd, bo->prime_fd, &handle);
if(ret){
err_exit("drmFDToPrimeHandle() failed");
}
log("handle:%d vs bo->handle:%d", handle, bo->handle);
destroy.handle = handle;
drmIoctl(fd, DRM_IOCTL_MODE_DESTROY_DUMB, &destroy);
}
int main(int argc, char **argv){
int fd;
fd = open("/dev/dri/card0", O_RDWR | O_CLOEXEC);
if(fd<=0){
printf("%s():%d\n", __func__,__LINE__);
return -1;
}
buf.width = 1024;
buf.height = 1;
create_dumb_get_prime_fd(fd, &buf);
send_fd(buf.prime_fd);
printf("press any key to exit\n");
getchar();
destroy_fd(fd, &buf);
close(fd);
return 0;
}
导入prime 部分
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/socket.h>
#include <sys/un.h>
#include <sys/ioctl.h>
#define log(fmt, args...) printf("%s():%d " fmt "\n", __func__, __LINE__, ##args)
#define SHARE_DMABUF_PATH "./tt"
#define err_return(fmt, args...) do{ \
printf("%s():%d " fmt "\n", __func__, __LINE__, ##args); \
return -1;\
}while(0)
#define err_return_void(fmt, args...) do{ \
printf("%s():%d " fmt "\n", __func__, __LINE__, ##args); \
return;\
}while(0)
int main(int argc, char **argv){
int ret = 0;
int fd;
int prime_fd = 5;
fd = open("/dev/importer", O_RDWR | O_CLOEXEC);
if(fd<=0){
printf("%s():%d\n", __func__,__LINE__);
return -1;
}
prime_fd = recv_prime_fd_from_socket();
// 把fd传递给import驱动进行访问
ret = ioctl(fd, 0, &prime_fd);
if(ret<0){
err_return("ioctl failed");
}
close(prime_fd);
close(fd);
return 0;
}
2.2.2 基于GEM的PRIME实现
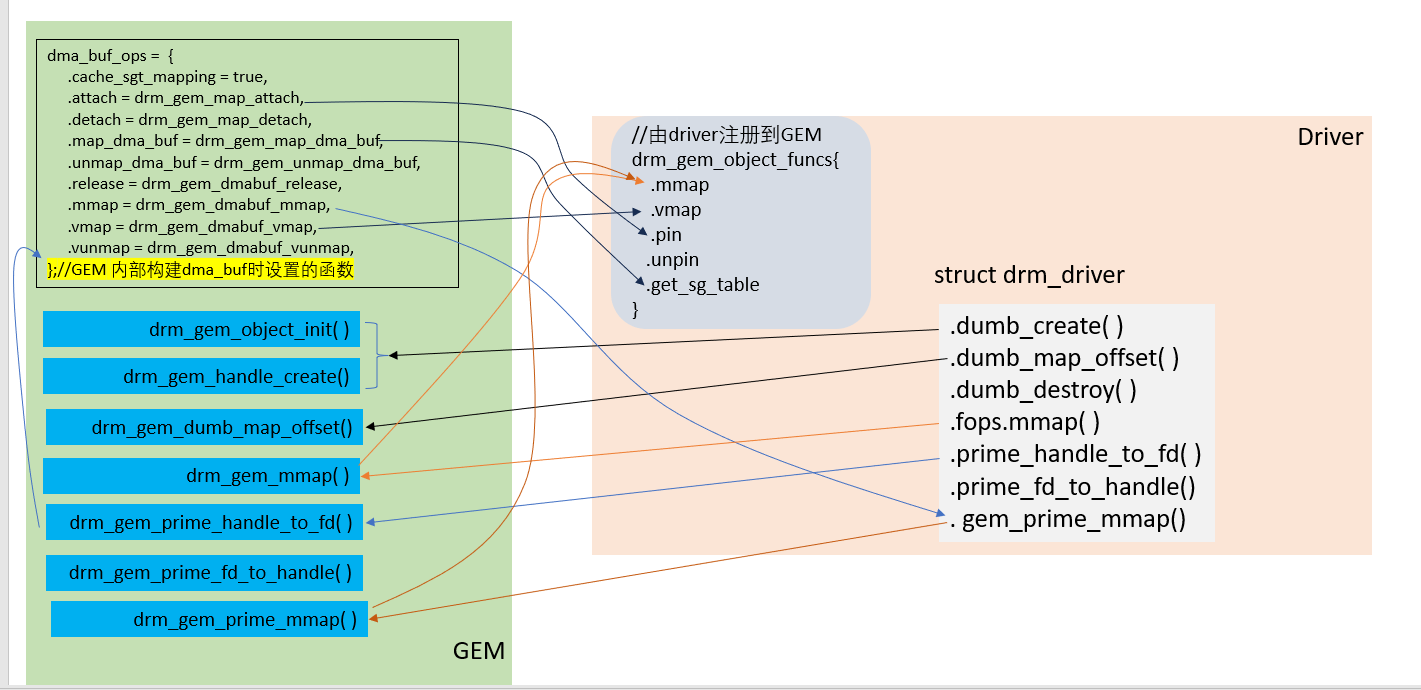
下图展示了基于GEM如何去实现PRIME特性,代码冗长,就不再贴出。
在实现driver时,主要工作有两个方面。
- 实现 struct drm_driver,如图所示,就是各函数指针直接设定为GEM的对应函数即可
- 实现 drm_gem_object_funcs. 只要实现图中drm_gem_object_funcs 各项即可。它所要实现接口对应调用关系如图所示,从中也可看出它们需要实现的内容。
2.3 系统现有的三种实现
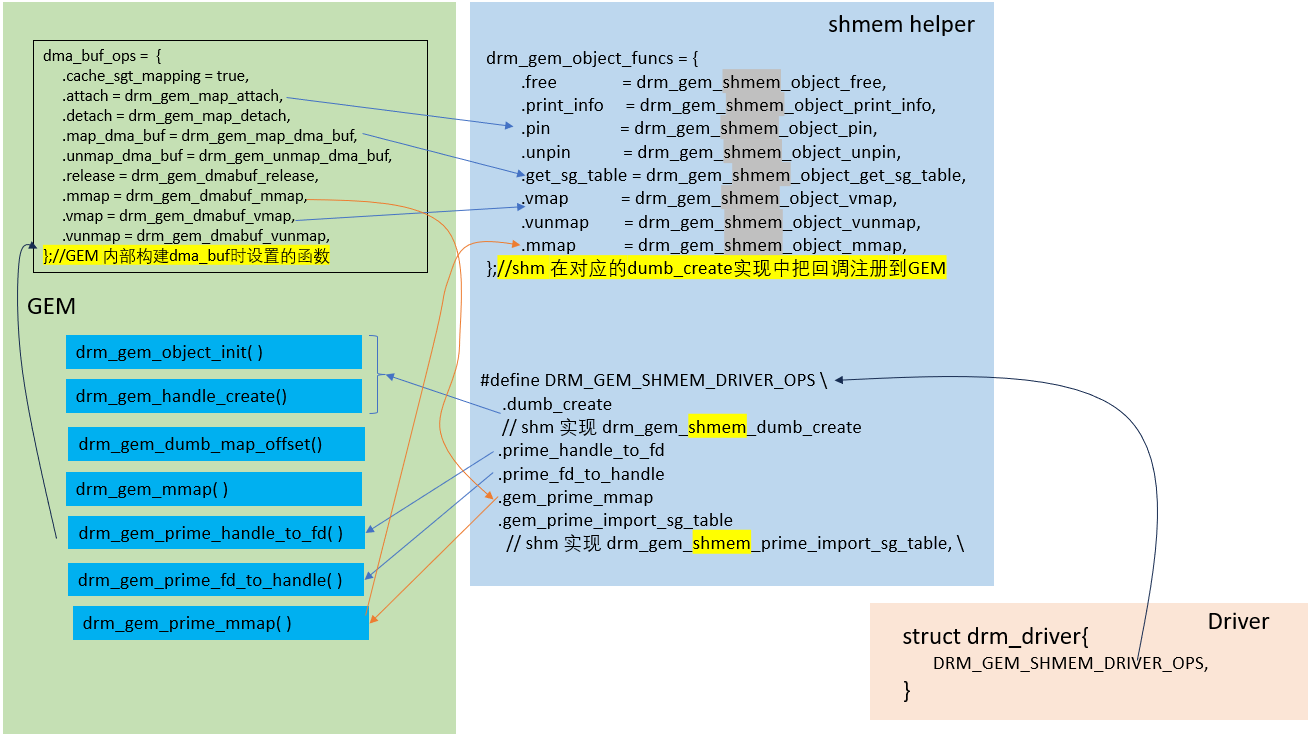
2.3.1 share memory
它是基于GEM和share memory实现的一组DRM操作,方便上层使用。
/**
* DRM_GEM_SHMEM_DRIVER_OPS - Default shmem GEM operations
*
* This macro provides a shortcut for setting the shmem GEM operations in
* the &drm_driver structure.
* 这个宏定义了一组shmem 的GEM操作,利用它可以快捷的在drm_driver结构中定义GEM操作。
*
* 在udl, hyperv, vkms, tiny, mgag200和gud 驱动中有用到它,可做参考。
*
*/
#define DRM_GEM_SHMEM_DRIVER_OPS \
.prime_handle_to_fd = drm_gem_prime_handle_to_fd, \
.prime_fd_to_handle = drm_gem_prime_fd_to_handle, \
.gem_prime_import_sg_table = drm_gem_shmem_prime_import_sg_table, \
.gem_prime_mmap = drm_gem_prime_mmap, \
.dumb_create = drm_gem_shmem_dumb_create
// GEM 提供的可供driver使用的struct file_operations
#define DEFINE_DRM_GEM_FOPS(name) \
static const struct file_operations name = {\
.owner = THIS_MODULE,\
.open = drm_open,\
.release = drm_release,\
.unlocked_ioctl = drm_ioctl,\
.compat_ioctl = drm_compat_ioctl,\
.poll = drm_poll,\
.read = drm_read,\
.llseek = noop_llseek,\
.mmap = drm_gem_mmap,\
}
在现有的udl, hyperv, vkms, tiny, mgag200和gud 驱动中,都使用了DEFINE_DRM_GEM_FOPS 和DRM_GEM_SHMEM_DRIVER_OPS 来简化driver的开发。
shem_helper的实现,主要就是针对share memory,实现drm_gem_object_funcs中定义的各个函数接口。
关系图如下:
2.3.1.1 create dumb
实现流程图如下:

2.3.1.2 mmap
实现流程图如下:

2.3.1.3 其他关于GEM的实现
实现流程图如下:

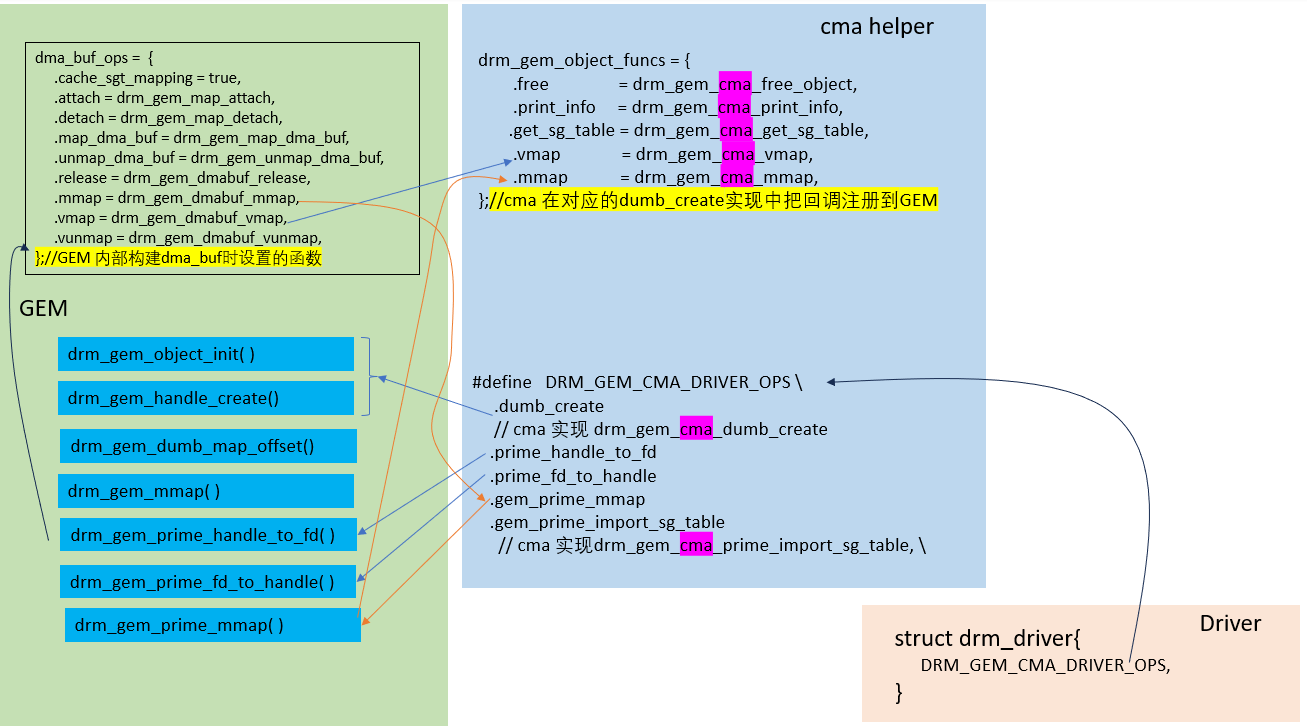
2.3.2 CMA
CMA: Contiguous Memory Allocator, CMA是一种内存分配机制,确保分配物理上连续的内存区域,它特别适用于需要具有连续内存的设备(例如显示控制器)的情况。
DRM的CMA helper提供了一种分配既具有物理连续性又适用于DMA(直接内存访问)操作的内存的方法,适合在硬件缺乏IOMMU(输入/输出内存管理单元)来映射分散的缓冲区的场景使用。
/**
* DRM_GEM_CMA_DRIVER_OPS_WITH_DUMB_CREATE - CMA GEM driver operations
* @dumb_create_func: callback function for .dumb_create
*
* This macro provides a shortcut for setting the default GEM operations in the
* &drm_driver structure.
*
* This macro is a variant of DRM_GEM_CMA_DRIVER_OPS for drivers that
* override the default implementation of &struct rm_driver.dumb_create. Use
* DRM_GEM_CMA_DRIVER_OPS if possible. Drivers that require a virtual address
* on imported buffers should use
* DRM_GEM_CMA_DRIVER_OPS_VMAP_WITH_DUMB_CREATE() instead.
*
* 使用到它的现有驱动有: aspeed, sti vc4 hisilicon ingenic shmobile xlnx imx sun4i tiny meson 等
*/
#define DRM_GEM_CMA_DRIVER_OPS_WITH_DUMB_CREATE(dumb_create_func) \
.dumb_create = (dumb_create_func), \
.prime_handle_to_fd = drm_gem_prime_handle_to_fd, \
.prime_fd_to_handle = drm_gem_prime_fd_to_handle, \
.gem_prime_import_sg_table = drm_gem_cma_prime_import_sg_table, \
.gem_prime_mmap = drm_gem_prime_mmap
#define DRM_GEM_CMA_DRIVER_OPS \
DRM_GEM_CMA_DRIVER_OPS_WITH_DUMB_CREATE(drm_gem_cma_dumb_create)
cma_helper的实现,主要就是针对CMA的特性调用DMA的接口实现drm_gem_object_funcs中定义的各个函数接口。
一些在CMA中实现的函数
| function | 功能 |
|---|---|
| drm_gem_cma_create | 分配由CMA内存支持的GEM对象。 |
| drm_gem_cma_dumb_create_internal | 为DRM帧缓冲创建内存区域。 |
| drm_gem_cma_dumb_map_offset | 将DRM帧缓冲的内存区域映射到用户空间。 |
| drm_gem_cma_mmap | 为用户空间访问映射分配的内存。 |
| drm_gem_cma_free_object | 释放GEM对象。 |
| drm_gem_cma_prime_get_sg_table | 获取导入PRIME缓冲区的散射/聚集表。 |
| drm_gem_cma_prime_import_sg_table | 从散射/聚集表导入GEM对象。 |
| drm_gem_cma_prime_mmap | 为PRIME mmap映射GEM对象。 |
| drm_gem_cma_prime_vmap和drm_gem_cma_prime_vunmap | 为PRIME映射和取消映射GEM对象。 |
关系图如下:
2.3.2.1 create dumb
实现流程图如下:

2.3.2.2 mmap
实现流程图如下:

2.3.2.3 其他关于GEM的实现
实现流程图如下:

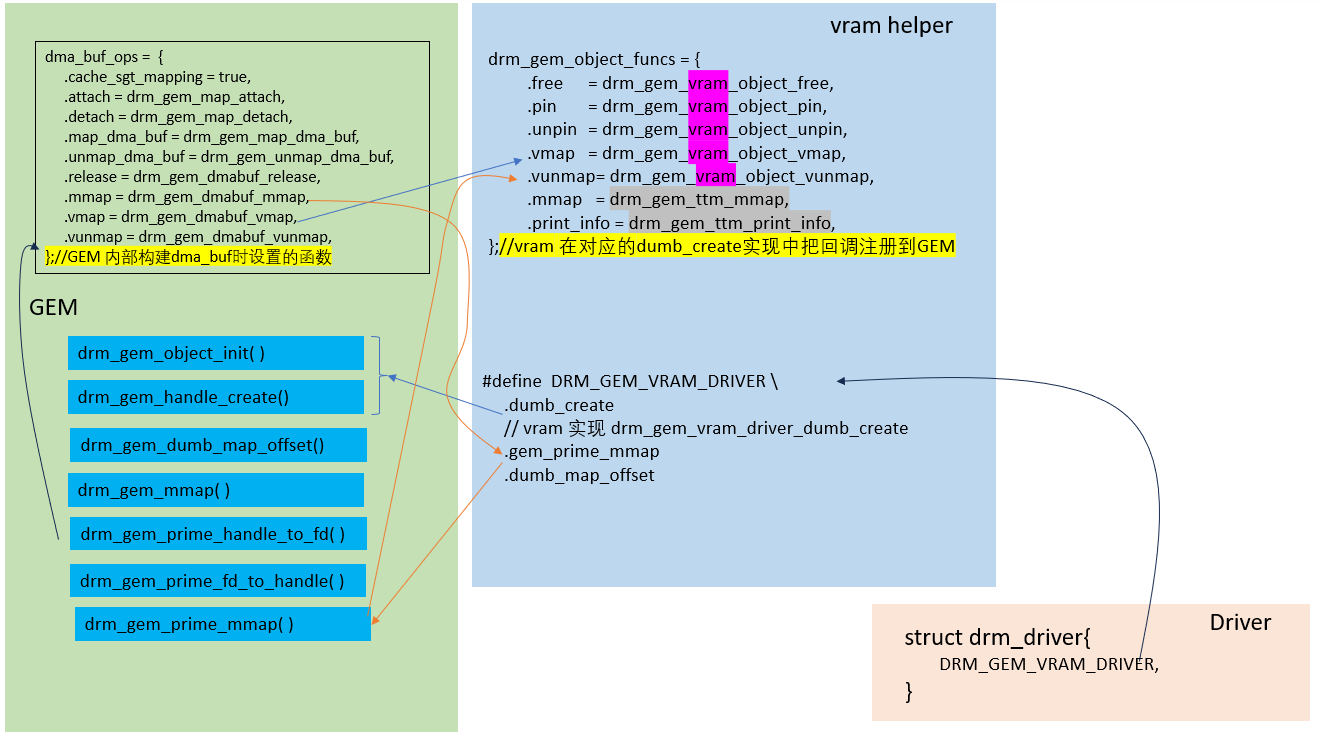
2.3.3 VRAM
VRAM: Video RAM
VRAM是显卡上的专用内存,用于存储图像、纹理、帧缓冲区和其他与图形相关的数据。在显卡中,VRAM是用于显示输出的内存池。它通常位于显卡芯片上,具有高带宽和低延迟,适用于图形渲染。VRAM的大小直接影响显卡的性能。更大的VRAM允许存储更多图像数据,从而提高图形处理速度。
/**
* define DRM_GEM_VRAM_DRIVER - default callback functions for \
&struct drm_driver
*
* Drivers that use VRAM MM and GEM VRAM can use this macro to initialize
* &struct drm_driver with default functions.
*
* 使用到它的现有驱动有: ast, tiny vboxvideo
*/
#define DRM_GEM_VRAM_DRIVER \
.debugfs_init = drm_vram_mm_debugfs_init, \
.dumb_create = drm_gem_vram_driver_dumb_create, \
.dumb_map_offset = drm_gem_ttm_dumb_map_offset, \
.gem_prime_mmap = drm_gem_prime_mmap
vram_helper的实现,主要是对TTM接口的封装调用来实现drm_gem_object_funcs中定义的各个函数接口。
GEM、 TTM使用场景
GEM通常用于UMA(Unified Memory Architecture)设备,而TTM更适用于具有专用视频RAM的设备。
关系图如下:
2.3.3.1 create dumb
实现流程图如下:

2.3.3.2 mmap
实现流程图如下:

2.3.3.3 其他关于GEM的实现
实现流程图如下:

3.KMS
3.1 相关概念
KMS(Kernel Mode Setting)是DRM框架的一个重要模块,
主要两个功能:
-
显示参数设置:
KMS负责设置显卡或图形适配器的模式,包括分辨率、刷新率、电源状态(休眠唤醒)等。
-
显示画面控制:
KMS管理显示缓冲区的切换、多图层的合成方式,以及每个图层的显示位置。
KMS的组成部分:
-
DRM FrameBuffer:
这是一个软件抽象,与硬件无关,描述了图层显示内容的信息,如宽度、高度、像素格式和行距等。
-
Planes:
基本的显示控制单元,每个图像都有一个Plane。Planes的属性控制着图像的显示区域、翻转方式和色彩混合方式。
-
CRTC:
CRTC负责将要显示的图像转化为底层硬件上的具体时序要求。它还负责帧切换、电源控制和色彩调整,可以连接多个Encoder,实现屏幕复制功能。
-
Encoder:
将内存中的像素转换成显示器所需的信号。
-
Connector:
连接器负责硬件设备的接入,如HDMI、VGA等,还可以获取设备的EDID和DPMS连接状态。
这些组件共同构成了一个完整的DRM显示控制过程。KMS的目标是适应现代显示设备的逻辑,使其能够更好地支持新特性,如显示覆盖、GPU加速和硬件光标等功能。
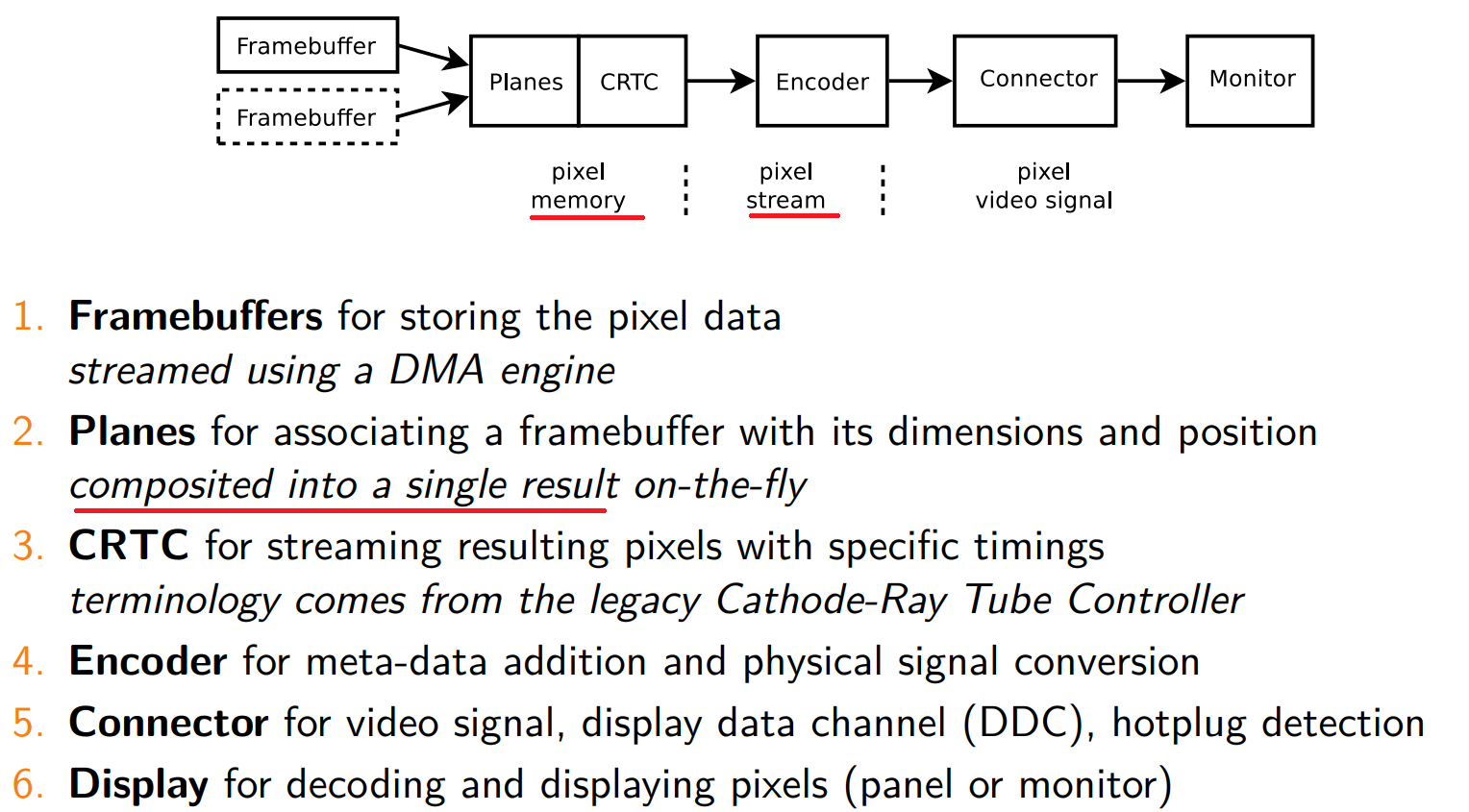
3.2 重要结构体
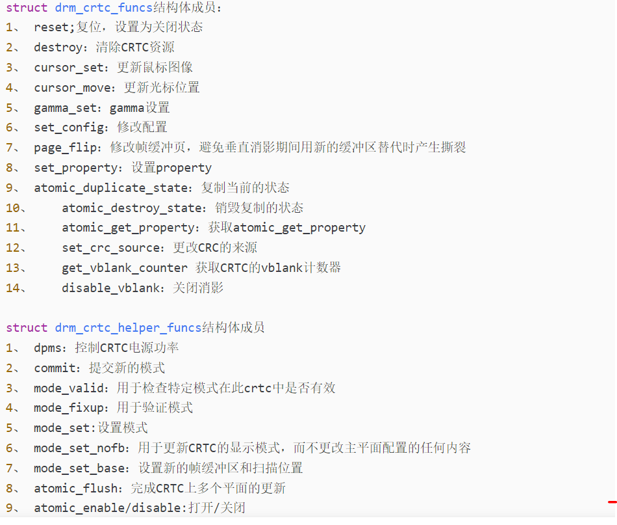


3.3 函数流程
devm_drm_dev_alloc()

drm_vblank_init()

drm_mode_config_init()

drmModeAddFb()

init CRTC

init plane

init connector

3.4 传统实现
drmModeSetCrtc

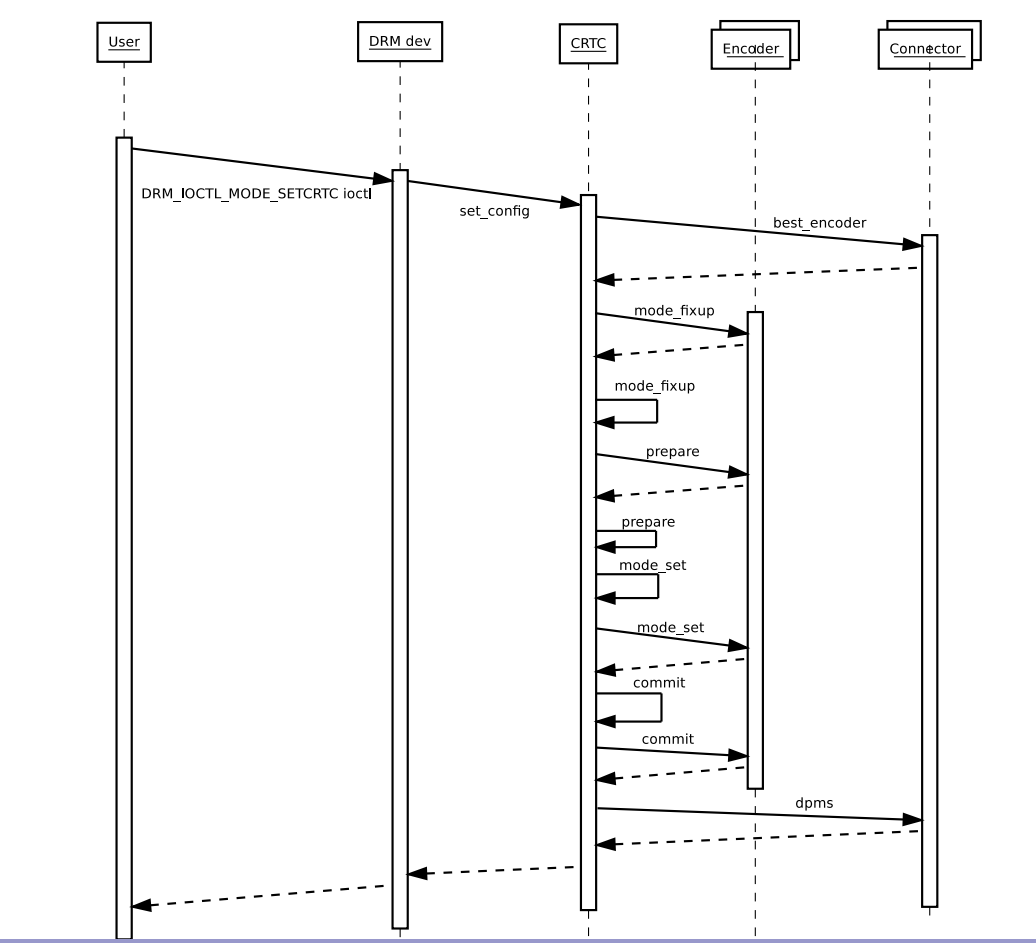
3.5 atomic实现
smaple code
#define _GNU_SOURCE
#include <errno.h>
#include <fcntl.h>
#include <stdbool.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
#include <time.h>
#include <unistd.h>
#include <xf86drm.h>
#include <xf86drmMode.h>
struct buffer_object {
uint32_t width;
uint32_t height;
uint32_t pitch;
uint32_t handle;
uint32_t size;
uint32_t fb_id;
};
struct buffer_object buf;
static int modeset_create_fb(int fd, struct buffer_object *bo)
{
struct drm_mode_create_dumb create = {};
struct drm_mode_map_dumb map = {};
create.width = bo->width;
create.height = bo->height;
create.bpp = 32;
drmIoctl(fd, DRM_IOCTL_MODE_CREATE_DUMB, &create);
bo->pitch = create.pitch;
bo->size = create.size;
bo->handle = create.handle;
drmModeAddFB(fd, bo->width, bo->height, 24, 32, bo->pitch,bo->handle, &bo->fb_id);
// drmModeAddFB2 可以传递多个handle
// drmModeAddFB(fd, bo->width, bo->height, 24, 32, bo->pitch,
// bo->handle, &bo->fb_id); //--> calling mode_config_funcs.fb_create()
map.handle = create.handle;
drmIoctl(fd, DRM_IOCTL_MODE_MAP_DUMB, &map);
return 0;
}
static void modeset_destroy_fb(int fd, struct buffer_object *bo)
{
struct drm_mode_destroy_dumb destroy = {};
drmModeRmFB(fd, bo->fb_id);
destroy.handle = bo->handle;
drmIoctl(fd, DRM_IOCTL_MODE_DESTROY_DUMB, &destroy);
}
static uint32_t get_property_id(int fd, drmModeObjectProperties *props, const char *name)
{
drmModePropertyPtr property;
uint32_t i, id = 0;
for (i = 0; i < props->count_props; i++) {
property = drmModeGetProperty(fd, props->props[i]);
if (!strcmp(property->name, name)){
id = property->prop_id;
}
drmModeFreeProperty(property);
if (id)
break;
}
return id;
}
int main(int argc, char **argv)
{
int fd;
drmModeConnector *conn;
drmModeRes *res;
drmModePlaneRes *plane_res;
drmModeObjectProperties *props;
drmModeAtomicReq *req;
uint32_t conn_id;
uint32_t crtc_id;
uint32_t plane_id;
uint32_t blob_id;
uint32_t property_crtc_id;
uint32_t property_mode_id;
uint32_t property_active;
uint32_t property_fb_id;
uint32_t property_crtc_x;
uint32_t property_crtc_y;
uint32_t property_crtc_w;
uint32_t property_crtc_h;
uint32_t property_src_x;
uint32_t property_src_y;
uint32_t property_src_w;
uint32_t property_src_h;
fd = open("/dev/dri/card0", O_RDWR | O_CLOEXEC);
res = drmModeGetResources(fd);
crtc_id = res->crtcs[0];
conn_id = res->connectors[0];
drmSetClientCap(fd, DRM_CLIENT_CAP_UNIVERSAL_PLANES, 1);
plane_res = drmModeGetPlaneResources(fd);
plane_id = plane_res->planes[0];
conn = drmModeGetConnector(fd, conn_id);
buf.width = conn->modes[0].hdisplay;
buf.height = conn->modes[0].vdisplay;
modeset_create_fb(fd, &buf);
drmSetClientCap(fd, DRM_CLIENT_CAP_ATOMIC, 1);
props = drmModeObjectGetProperties(fd, conn_id, DRM_MODE_OBJECT_CONNECTOR);
property_crtc_id = get_property_id(fd, props, "CRTC_ID");
drmModeFreeObjectProperties(props);
props = drmModeObjectGetProperties(fd, crtc_id, DRM_MODE_OBJECT_CRTC);
property_active = get_property_id(fd, props, "ACTIVE");
property_mode_id = get_property_id(fd, props, "MODE_ID");
drmModeFreeObjectProperties(props);
drmModeCreatePropertyBlob(fd, &conn->modes[0], sizeof(conn->modes[0]), &blob_id);
req = drmModeAtomicAlloc();
drmModeAtomicAddProperty(req, crtc_id, property_active, 1);
drmModeAtomicAddProperty(req, crtc_id, property_mode_id, blob_id);
drmModeAtomicAddProperty(req, conn_id, property_crtc_id, crtc_id);
drmModeAtomicCommit(fd, req, DRM_MODE_ATOMIC_ALLOW_MODESET, NULL);
drmModeAtomicFree(req);
/* get plane properties */
props = drmModeObjectGetProperties(fd, plane_id, DRM_MODE_OBJECT_PLANE);
property_crtc_id = get_property_id(fd, props, "CRTC_ID");
property_fb_id = get_property_id(fd, props, "FB_ID");
property_crtc_x = get_property_id(fd, props, "CRTC_X");
property_crtc_y = get_property_id(fd, props, "CRTC_Y");
property_crtc_w = get_property_id(fd, props, "CRTC_W");
property_crtc_h = get_property_id(fd, props, "CRTC_H");
property_src_x = get_property_id(fd, props, "SRC_X");
property_src_y = get_property_id(fd, props, "SRC_Y");
property_src_w = get_property_id(fd, props, "SRC_W");
property_src_h = get_property_id(fd, props, "SRC_H");
drmModeFreeObjectProperties(props);
/* atomic plane update */
req = drmModeAtomicAlloc();
drmModeAtomicAddProperty(req, plane_id, property_crtc_id, crtc_id);
drmModeAtomicAddProperty(req, plane_id, property_fb_id, buf.fb_id);
drmModeAtomicAddProperty(req, plane_id, property_crtc_x, 50);
drmModeAtomicAddProperty(req, plane_id, property_crtc_y, 50);
drmModeAtomicAddProperty(req, plane_id, property_crtc_w, 320);
drmModeAtomicAddProperty(req, plane_id, property_crtc_h, 320);
drmModeAtomicAddProperty(req, plane_id, property_src_x, 0);
drmModeAtomicAddProperty(req, plane_id, property_src_y, 0);
drmModeAtomicAddProperty(req, plane_id, property_src_w, 320 << 16);
drmModeAtomicAddProperty(req, plane_id, property_src_h, 320 << 16);
drmModeAtomicCommit(fd, req, 0, NULL);
drmModeAtomicFree(req);
printf("drmModeAtomicCommit SetPlane done\n");
getchar();
modeset_destroy_fb(fd, &buf);
drmModeFreeConnector(conn);
drmModeFreePlaneResources(plane_res);
drmModeFreeResources(res);
close(fd);
return 0;
}
drmModeGetProperty

drmModeAtomicCommit

3.6 vkms
VKMS(Virtual Kernel Modesetting)是 Linux 内核中的一个软件模拟 KMS 驱动程序,主要用于测试和在无显示硬件的机器上运行 X(或类似的图形界面)

4 MISC
4.1 modifier
在 DRM(Direct Rendering Manager) 中,modifier 是用于描述图像帧的内存存储方式的标志。让我们详细了解一下:
- DRM Modifier 是什么?
- DRM Modifier 是一个 64 位的、厂商前缀的、半透明的无符号整数。
- 大多数 modifier 表示图像的具体、厂商特定的平铺格式。
- 为什么需要 Modifier?
- 图像帧在内存中的存储方式可能因硬件和驱动程序而异。
- Modifier 描述了像素到内存样本之间的转换机制,以及缓冲区的实际内存存储方式。
- 常见 Modifier 示例:
- LINEAR Modifier:最直接的 Modifier,其中每个像素具有连续的存储,像素在内存中的位置可以通过步幅轻松计算。
- TILED Modifier:描述了像素以 4x4 块的形式存储,按行主序排列。
- 其他 Modifier 可能涉及到更复杂的内存访问机制,例如平铺和可能的压缩。
- 应用场景:
- DRM Modifier 在跨设备的缓冲区共享中非常重要,例如在不同的图形硬件之间共享图像帧。
- 它们也用于描述图像帧的格式,例如颜色定义和像素格式。
总之,DRM Modifier 是描述图像帧内存存储方式的关键标志,对于图形硬件和驱动程序之间的交互至关重要。
4.2 gamma
在 DRM(Direct Rendering Manager) 中,gamma 是用于图像颜色校正的一个重要概念。让我详细解释一下:
- Gamma 是什么?
- Gamma 是一个非线性的颜色校正过程,用于调整显示设备的亮度和对比度。
- 它主要影响图像的中间和暗部,而不是亮部。
- Gamma 校正的作用:
- Gamma 校正用于补偿显示设备的非线性响应。
- 显示设备(例如显示器、电视)对输入信号的响应不是线性的,而是呈现出一种非线性的亮度-输入关系。
- 通过应用 Gamma 校正,可以使图像在显示时更接近人眼感知的线性亮度。
- Gamma 曲线:
- Gamma 曲线描述了输入信号和显示亮度之间的关系。
- 通常,显示设备的 Gamma 曲线是一个幂函数,通常在 2.2 到 2.5 之间。
- 应用场景:
- Gamma 校正在图形、视频和游戏中都很重要。
- 在图像处理和显示中,应用正确的 Gamma 曲线可以确保图像的亮度和对比度在不同设备上保持一致。
总之,Gamma 是一种用于调整显示设备响应的非线性颜色校正方法,以确保图像在不同设备上呈现一致的亮度和对比度。
4.3 Blob
当涉及到 DRM(Direct Rendering Manager)中的“blob”时,我们实际上在讨论一种特定类型的属性。让我详细解释一下:
1 什么是 Blob?
- 在 DRM 中,Blob 是一种特殊的属性,用于存储自定义数据块。它允许用户空间应用程序将自定义结构体数据传递给内核空间。
- Blob 通常用于存储一些不适合使用标准属性的数据,例如模式信息、LUT(查找表)数据、校准数据等。
2 Blob 的结构和用法:
-
Blob 由两部分组成:
-
Blob ID:每个 Blob 都有一个唯一的 ID,用于在内核中标识该 Blob。
-
Blob 数据:这是一个自定义长度的内存块,可以存储任何类型的数据。
-
-
Blob 可以存储各种信息,例如显示模式(mode)的详细信息、颜色校准数据、Gamma 表等。
3 Blob 的示例用途:
-
模式信息(Mode Information):Blob 可以存储显示模式的详细信息,例如分辨率、刷新率、像素格式等。
-
颜色校准数据:如果您需要在显示设备上进行颜色校准,可以使用 Blob 存储校准数据。
-
Gamma 表:Gamma 表用于调整显示设备的亮度和对比度。这些数据可以存储在 Blob 中。
4 如何操作 Blob?
-
用户空间应用程序可以通过 DRM 接口来创建、获取和设置 Blob。
-
创建 Blob:使用 drmModeCreatePropertyBlob 函数来创建一个 Blob,并将自定义数据传递给内核。
-
获取 Blob 数据:使用 drmModeGetPropertyBlob 函数来获取 Blob 中存储的数据。
-
设置 Blob 数据:使用 drmModeAtomicAddProperty 函数将 Blob ID 添加到 Atomic 请求中,从而修改 Blob 数据。
5 示例
#include <xf86drm.h>
#include <xf86drmMode.h>
int main() {
int drm_fd = open("/dev/dri/card0", O_RDWR); // 打开 DRM 设备
// 读取 GPU 固件数据(假设存在 firmware.bin 文件)
FILE *firmware_file = fopen("firmware.bin", "rb");
fseek(firmware_file, 0, SEEK_END);
size_t firmware_size = ftell(firmware_file);
fseek(firmware_file, 0, SEEK_SET);
void *firmware_data = malloc(firmware_size);
fread(firmware_data, 1, firmware_size, firmware_file);
fclose(firmware_file);
// 创建 DRM blob
uint32_t blob_handle;
drmModeCreatePropertyBlob(drm_fd, firmware_data, firmware_size, &blob_handle);
// 将 blob 设置为 GPU 的固件
// ...(其他操作,例如加载到显卡)
// 清理资源
free(firmware_data);
close(drm_fd);
return 0;
}
总之,Blob 是一种用于存储自定义数据的特殊属性,允许用户空间应用程序与内核交换非标准化的信息。它在 DRM 中的应用范围很广,例如显示模式、颜色校准和 Gamma 表等。
4.4 drmModeSetCrtc与drmModePageFlip
在 Linux 图形显示框架中,drmModeSetCrtc、drmModePageFlip 和 drmModeSetPlane 是三个重要的函数,它们用于更新显示内容,但在功能和执行时机上存在一些区别:
drmModeSetCrtc:drmModeSetCrtc是最核心的函数之一,负责建立从帧缓存到显示器连接器的关联。- 它执行两个主要任务:
- 更新画面:切换显示缓冲区,合成多图层,设置每个图层的显示位置。
- 设置显示参数:包括分辨率、刷新率、电源状态(休眠唤醒)等。
drmModePageFlip:drmModePageFlip也用于更新显示内容,但与drmModeSetCrtc最大的区别在于:- 它只会在 VSYNC 到来后才真正执行帧缓冲区切换动作。
- 等待 VSYNC 可以避免画面撕裂(tearing)现象。
- 适用于需要同步刷新的场景,如视频播放、游戏等。
drmModeSetPlane:drmModeSetPlane用于设置硬件平面(overlay plane)的参数。- 硬件平面是一种特殊的图层,可以在其他图层之上叠加显示。
- 适用于实现视频叠加、OSD(On-Screen Display)等功能。
总结:
drmModeSetCrtc负责整体显示设置。drmModePageFlip等待 VSYNC 后切换帧缓冲区。drmModeSetPlane控制硬件平面的显示。
5 IOCTL
DRM_IOCTL_VERSION
它通过主要、次要和补丁程序级别的三元组来标识驱动程序版本。
- 这些信息在初始化时被打印到内核日志中
- 通过
DRM_IOCTL_VERSIONioctl 传递到用户空间。
驱动程序的描述是一个纯粹的信息字符串,通过 DRM_IOCTL_VERSION ioctl 传递给用户空间,但在内核中没有其他用途。驱动程序的日期以 YYYYMMDD 格式表示,用于标识驱动程序的最新修改日期。由于大多数驱动程序未能更新它,其值基本上是无用的。
DRM_IOCTL_GET_UNIQUE
它允许用户空间程序查询与 DRM 设备相关的唯一标识符。这个接口通常用于获取设备的 UUID 或其他唯一标识,以便在多个设备之间进行区分。
DRM_IOCTL_SET_UNIQUE
它允许用户空间程序设置 DRM 设备的唯一名称。让我们深入了解一下这个接口的作用和实现。
- 接口作用:
DRM_IOCTL_SET_UNIQUE允许用户空间程序使用指定的字符串设置 DRM 设备的唯一名称。- 这个唯一名称通常用于标识不同的 DRM 设备,以便在多个设备之间进行区分。
- 实现细节:
- 在 Linux 内核中,
DRM_IOCTL_SET_UNIQUE的实现可能因不同的 DRM 驱动而异。 - 用户空间程序可以通过调用相应的 ioctl 函数来设置设备的唯一名称。
- 在 Linux 内核中,
DRM_IOCTL_IRQ_BUSID
它用于基于总线 ID(busid)为 PCI 设备获取中断请求(IRQ)。在过去,这个接口是通用的 DRM 模块函数,可以为多个不同的设备提供服务。然而,现在它可能需要更改,以仅返回与特定 drm_device_t 相关联的设备的中断号。
DRM_IOCTL_GET_CLIENT
它用于查询 DRM 设备的客户端信息。让我们来详细了解一下这个接口的作用和实现。
- 接口作用:
DRM_IOCTL_GET_CLIENT允许用户空间程序查询与 DRM 设备相关的客户端信息。- 这个接口通常用于获取客户端的唯一标识符或其他相关信息,以便在多个客户端之间进行区分。
- 实现细节:
- 在 Linux 内核中,
DRM_IOCTL_GET_CLIENT的实现可能因不同的 DRM 驱动而异。 - 通过调用
drmGetBusid()函数,用户空间程序可以获取与总线 ID(busid)相关的客户端信息。 - 请注意,这个接口的具体实现可能因不同的驱动而有所不同,因此您可以查阅特定驱动的文档或源代码以获取更详细的信息。
- 在 Linux 内核中,
DRM_IOCTL_GET_STATS
它允许用户空间程序查询与 DRM 设备相关的统计信息。让我们来详细了解一下这个接口的作用和实现。
- 接口作用:
DRM_IOCTL_GET_STATS允许用户空间程序获取与 DRM 设备相关的统计数据。- 这个接口通常用于查询设备的性能指标、资源使用情况、错误统计等信息。
- 实现细节:
- 在 Linux 内核中,
DRM_IOCTL_GET_STATS的实现可能因不同的 DRM 驱动而异。 - 用户空间程序可以通过调用相应的 ioctl 函数来获取统计数据。
- 请注意,这个接口的具体实现可能因不同的驱动而有所不同,因此您可以查阅特定驱动的文档或源代码以获取更详细的信息。
- 在 Linux 内核中,
DRM_IOCTL_GET_CAP
它允许用户空间程序查询与 DRM 设备相关的能力信息。让我们来详细了解一下这个接口的作用和实现。
- 接口作用:
DRM_IOCTL_GET_CAP允许用户空间程序获取与 DRM 设备相关的能力数据。- 这个接口通常用于查询设备支持的功能、特性和限制。
- 实现细节:
- 在 Linux 内核中,
DRM_IOCTL_GET_CAP的实现可能因不同的 DRM 驱动而异。 - 用户空间程序可以通过调用相应的 ioctl 函数来获取能力数据。
- 请注意,这个接口的具体实现可能因不同的驱动而有所不同,因此您可以查阅特定驱动的文档或源代码以获取更详细的信息。
- 在 Linux 内核中,
DRM_IOCTL_SET_CLIENT_CAP
它允许用户空间程序设置与 DRM 设备相关的能力信息。让我们来详细了解一下这个接口的作用和实现。
- 接口作用:
DRM_IOCTL_SET_CLIENT_CAP允许用户空间程序设置与 DRM 设备相关的能力数据。- 这个接口通常用于查询设备支持的功能、特性和限制。
- 实现细节:
- 在 Linux 内核中,
DRM_IOCTL_SET_CLIENT_CAP的实现可能因不同的 DRM 驱动而异。 - 用户空间程序可以通过调用相应的 ioctl 函数来设置能力数据。
- 请注意,这个接口的具体实现可能因不同的驱动而有所不同,因此您可以查阅特定驱动的文档或源代码以获取更详细的信息。
- 在 Linux 内核中,
- DRM_CLIENT_CAP_ASPECT_RATIO:
-
是一个客户端能力标志,用于指示用户空间应用程序是否支持图像的纵横比信息。如果应用程序支持此标志,内核将在模式中传递纵横比信息。这对于显示图像时保持正确的纵横比非常重要。
-
如果设置为 1,DRM 内核将向用户空间公开原子属性。这隐式启用了 DRM_CLIENT_CAP_UNIVERSAL_PLANES 和 DRM_CLIENT_CAP_ASPECT_RATIO。如果驱动程序不支持原子模式设置,启用此功能将失败并返回 -EOPNOTSUPP 错误。这个功能是在内核版本 4.0 中引入的1。
-
DRM_IOCTL_WAIT_VBLANK
它允许用户空间程序在指定的vblank事件发生时阻塞或请求信号。让我们来详细了解一下这个接口的作用和实现:
- 接口作用:
DRM_IOCTL_WAIT_VBLANK允许用户空间程序在指定的vblank事件发生时阻塞或请求信号。- 这个接口通常用于与显示相关的同步操作,例如在进行页面翻转时等待vblank。
- 实现细节:
- DRM 核心处理大部分vblank管理逻辑,包括过滤掉虚假中断、保持无竞争的空白计数、处理计数器回绕和重置,以及保持使用计数。
- 用户空间程序可以通过执行相应的 ioctl 函数来使用这个接口。
- 这个机制确保只有经过身份验证的调用者才能访问特定的 DRM 功能。
- 垂直同步(VSYNC):
- 在图形渲染中,垂直同步是一种技术,用于确保图像在显示器上的刷新与显示器的垂直空白期(vertical blanking interval)同步。
- vblank(垂直空白期)是显示器在绘制一帧图像后,准备绘制下一帧之间的时间间隔。
- drmWaitVBlank 函数:
- 这个函数用于等待垂直同步信号。
- 它接受一个 DRM 设备文件描述符(file descriptor)和一个表示显示输出的 CRTC(Cathode Ray Tube Controller)的 ID。 当垂直同步信号到达时,函数会返回。
- 在游戏开发和图形渲染中,drmWaitVBlank 可以用于确保页面翻转(page flip)与垂直同步对齐,从而避免屏幕撕裂(tearing)。
DRM_IOCTL_MODE_GETGAMMA
用于从 Linux 内核模式设置(KMS) 中获取特定 CRTC(Cathode Ray Tube Controller) 的 伽马校正(Gamma Correction) 信息.
详情如下:
- 伽马校正是什么?
- 伽马校正 是一种图像处理技术,用于调整显示设备的亮度和对比度。
- 它通过改变像素的亮度值来实现,以便更准确地显示不同亮度级别的图像。
- DRM_IOCTL_MODE_GETGAMMA 的作用
- 通过调用
DRM_IOCTL_MODE_GETGAMMA,应用程序可以获取有关特定 CRTC 的伽马校正信息。 - 这些信息可能包括伽马校正曲线、亮度和对比度的调整等。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_GETGAMMA,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_MODE_DIRTYFB
用于定义一个帧缓冲区区域为“脏”(数据已更改,因此需要重新显示)。这个 ioctl 使用了 drm_mode_fb_dirty_cmd 结构,其中包含一个 num_clips 字段,指示更改的区域数量.
- 帧缓冲区是什么?
- 帧缓冲区 是一个抽象的内存对象,用于向 CRTC 扫描输出像素。
- 应用程序通过
DRM_IOCTL_MODE_ADDFB(2)ioctl 显式请求创建帧缓冲区,并接收一个不透明的句柄,可以传递给 KMS CRTC 控制、平面配置和页面翻转功能。 - 帧缓冲区依赖于底层内存管理器进行低级内存操作。
- DRM_IOCTL_MODE_DIRTYFB 的作用
- 通过调用
DRM_IOCTL_MODE_DIRTYFB,应用程序可以将特定帧缓冲区区域标记为“脏”。 - 这通常用于通知显示系统需要重新扫描和显示更改的像素数据。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_DIRTYFB,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_MODE_ATOMIC
用于在 Linux 内核模式设置(KMS) 中执行 原子操作(Atomic Operation)。详情如下:
- KMS 是什么?
- KMS(Kernel Mode Setting) 是一种内核级别的图形显示设置机制,用于管理显示设备的模式和状态。
- 它允许用户空间应用程序与内核交互,以配置显示输出。
- 原子操作的概念
- 在图形渲染中,原子操作 是指一组状态更改,要么全部成功应用,要么全部失败,不会出现部分应用的情况。
- 在 KMS 中,原子操作用于一次性更新多个显示对象的状态,例如 CRTC、平面、连接器等。
- DRM_IOCTL_MODE_ATOMIC 的作用
- 通过调用
DRM_IOCTL_MODE_ATOMIC,应用程序可以提交一组原子操作,以更新显示管道的状态。 - 这些操作可以包括更改 CRTC 模式、平面配置、连接器状态等。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_ATOMIC,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_CRTC_GET_SEQUENCE
用于从 Linux 内核模式设置(KMS) 中获取特定 CRTC(Cathode Ray Tube Controller) 的 帧序列(Frame Sequence) 信息.
详情如下:
- CRTC 是什么?
- CRTC 是显示控制器,负责将图形数据发送到显示设备(例如显示器或电视)。
- 它管理像素时钟、扫描线和帧缓冲区的刷新。
- 帧序列是什么?
- 在图形渲染中,帧序列 是指显示设备刷新图像的顺序。
- 通过调用
DRM_IOCTL_CRTC_GET_SEQUENCE,应用程序可以获取有关特定 CRTC 的帧序列信息,例如当前帧数、垂直同步信号等。
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_CRTC_GET_SEQUENCE,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_CRTC_QUEUE_SEQUENCE
用于在 Linux 内核模式设置(KMS) 中将特定 CRTC(Cathode Ray Tube Controller) 的帧序列信息添加到队列中.
以下是关于 DRM_IOCTL_CRTC_QUEUE_SEQUENCE 的一些要点:
- CRTC 是什么?
- CRTC 是显示控制器,负责将图形数据发送到显示设备(例如显示器或电视)。
- 它管理像素时钟、扫描线和帧缓冲区的刷新。
- 帧序列是什么?
- 在图形渲染中,帧序列 是指显示设备刷新图像的顺序。
- 通过调用
DRM_IOCTL_CRTC_QUEUE_SEQUENCE,应用程序可以将特定 CRTC 的帧序列信息添加到队列中。
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_CRTC_QUEUE_SEQUENCE,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
Magic & Master
DRM_IOCTL_GET_MAGIC
是一对 IOCTL(Input/Output Control)命令。详情如下:
- 魔数/幻数字(Magic Number)的作用
- 在图形设备驱动中,
DRM_IOCTL_GET_MAGIC用于设置魔数/幻数字,以进行 GEM ioctl 权限检查。 - 魔数是一个32位的标识符,用于验证对图形资源的访问权限。
- 在图形设备驱动中,
- 具体操作
DRM_IOCTL_GET_MAGIC函数会返回一个32位的魔数,然后将该魔数传递给 DRM-Master。- DRM-Master 使用此魔数通过
DRM_IOCTL_AUTH_MAGIC给发起鉴权的非 DRM-Master 应用程序授权。
DRM_IOCTL_AUTH_MAGIC
它用于对非 DRM 主用户空间程序进行身份验证。让我们详细了解一下这个接口的作用和实现:
- 接口作用:
DRM_IOCTL_AUTH_MAGIC用于对非 DRM 主用户空间程序进行身份验证。- 具体流程如下:
- 非 DRM 主用户空间程序通过执行
DRM_IOCTL_GET_MAGICioctl 从 DRM 设备获取一个唯一的令牌(32 位魔数)。 - 然后,用户空间程序将此令牌传递给 DRM 主(例如通过 IPC 或 X 客户端中的 DRI2Authenticate 请求)。
- DRM 主进程随后使用
DRM_IOCTL_AUTH_MAGICioctl 将令牌发送回 DRM 设备。 - 设备根据接收到的令牌,授予发起身份验证的非 DRM 主应用特殊权限。
- 非 DRM 主用户空间程序通过执行
- 实现细节:
- 身份验证令牌允许非 DRM 主进程执行特定的特权操作。
- 通过将令牌与相应的文件描述符(fd)关联,设备授权应用访问特定资源或执行受限操作。
- 这种机制确保只有经过身份验证的调用者才能访问特定的 DRM 功能。

DRM_IOCTL_SET_MASTER
它允许用户空间程序成为唯一的 DRM 主显示管理程序。执行此 ioctl 后,该程序获得了独占的权限,用于管理与显示相关的操作。相反,DRM_IOCTL_DROP_MASTER ioctl 可用于放弃 DRM 主身份。通常情况下,X 服务器(Xorg)充当 DRM 主。
其他非 DRM 主用户空间程序可以通过 DRM-Auth 进行身份验证。具体过程如下:
- 执行
DRM_IOCTL_GET_MAGICioctl,从 DRM 设备获取一个唯一的令牌(魔数)。 - 将此令牌传递给 DRM 主(例如通过 IPC 或 X 客户端中的 DRI2Authenticate 请求)。
- DRM 主进程随后使用
DRM_IOCTL_AUTH_MAGICioctl 将令牌发送回 DRM 设备。 - 基于接收到的令牌,设备授予发起身份验证的非 DRM 主应用特殊权限。
这个身份验证令牌允许非 DRM 主进程执行特定的特权操作。通过将令牌与相应的文件描述符(fd)关联,设备授权应用访问特定资源或执行受限操作。这种机制确保只有经过身份验证的调用者才能访问特定的 DRM 功能。
DRM_IOCTL_DROP_MASTER
它允许用户空间程序放弃 DRM 主身份。让我们详细了解一下这个接口的作用和实现:
- 接口作用:
DRM_IOCTL_DROP_MASTER允许用户空间程序放弃 DRM 主身份。- 当程序执行此 ioctl 时,它会失去独占管理显示相关操作的特权。
- 相反,
DRM_IOCTL_SET_MASTERioctl 可用于成为 DRM 主。
- 实现细节:
- 通过执行
DRM_IOCTL_DROP_MASTER,用户空间程序可以放弃 DRM 主身份。 - 这在需要切换 DRM 主时很有用,例如在关闭/打开主设备节点时。
- 通常情况下,X 服务器(Xorg)充当 DRM 主。
- 通过执行
GEM
DRM_IOCTL_GEM_CLOSE
它用于关闭 GEM 缓冲区(Graphics Execution Manager)。让我们详细了解一下这个接口的作用和实现:
- 接口作用:
DRM_IOCTL_GEM_CLOSE用于关闭 GEM 缓冲区。- 在执行此 ioctl 后,GEM 缓冲区的句柄将不再可用于当前进程,并且可能被 GEM API 重新用于新的 GEM 对象。
- 实现细节:
- 用户空间程序可以通过执行
DRM_IOCTL_GEM_CLOSE来关闭 GEM 缓冲区。 - 这在释放资源或管理内存时非常有用。
- 请注意,GEM 缓冲区的关闭不会立即释放内存,而是将其标记为不再使用,以便稍后进行回收。
- 用户空间程序可以通过执行
DRM_IOCTL_GEM_FLINK
它用于为 GEM 缓冲区(Graphics Execution Manager)创建一个名称。让我们详细了解一下这个接口的作用和实现:
- 接口作用:
DRM_IOCTL_GEM_FLINK用于为 GEM 缓冲区创建一个名称。- 在执行此 ioctl 后,您可以使用这个名称来引用该 GEM 缓冲区。
- 实现细节:
- 用户空间程序可以通过执行
DRM_IOCTL_GEM_FLINK来为 GEM 缓冲区创建一个名称。 - 这在需要在不同进程之间引用 GEM 对象时非常有用。
- 请注意,这个名称不能直接用于在 DRM API 中引用对象,应用程序必须使用
DRM_IOCTL_GEM_FLINK和DRM_IOCTL_GEM_OPENioctl 分别将句柄转换为名称和名称转换为句柄。
- 用户空间程序可以通过执行
DRM_IOCTL_GEM_OPEN
它用于为 GEM 缓冲区(Graphics Execution Manager)创建一个名称。让我们详细了解一下这个接口的作用和实现:
- 接口作用:
DRM_IOCTL_GEM_OPEN允许用户空间程序为 GEM 缓冲区创建一个名称。- 在执行此 ioctl 后,您可以使用这个名称来引用该 GEM 缓冲区。
- 实现细节:
- 用户空间程序可以通过执行
DRM_IOCTL_GEM_OPEN来为 GEM 缓冲区创建一个名称。 - 这在需要在不同进程之间引用 GEM 对象时非常有用。
- 请注意,这个名称不能直接用于在 DRM API 中引用对象,应用程序必须使用
DRM_IOCTL_GEM_FLINK和DRM_IOCTL_GEM_OPENioctl 分别将句柄转换为名称和名称转换为句柄。
- 用户空间程序可以通过执行
DRM_IOCTL_PRIME_HANDLE_TO_FD
它用于将 GEM 缓冲区(Graphics Execution Manager)的句柄转换为文件描述符(fd)。让我们详细了解一下这个接口的作用和实现:
- 接口作用:
DRM_IOCTL_PRIME_HANDLE_TO_FD允许用户空间程序将 GEM 缓冲区的句柄转换为文件描述符。- 这在需要在不同进程之间共享 GEM 缓冲区时非常有用,例如用于跨进程的纹理共享。
- 实现细节:
- 用户空间程序可以通过执行
DRM_IOCTL_PRIME_HANDLE_TO_FD来获取文件描述符。 - 这个接口通常与其他进程之间的 IPC(进程间通信)一起使用,以便共享 GEM 缓冲区。
- 请注意,这个接口的实现可能因不同的 DRM 驱动而有所不同,具体细节可以查阅特定驱动的文档或源代码。
- 用户空间程序可以通过执行
- 相关CMD DRM_IOCTL_PRIME_FD_TO_HANDLE
Resource
DRM_IOCTL_MODE_GETRESOURCES
它允许用户空间程序获取与 DRM 设备相关的资源信息。让我们详细了解一下这个接口的作用和实现:
- 接口作用:
DRM_IOCTL_MODE_GETRESOURCES用于获取与 DRM 设备相关的资源信息。- 这个接口通常用于查询设备的帧缓冲、连接器、CRTC(显示管道)和编码器的数量和标识符。
- 实现细节:
- 用户空间程序可以通过执行
DRM_IOCTL_MODE_GETRESOURCES来获取资源信息。 - 返回的结构体
drm_mode_card_res包含了帧缓冲、连接器、CRTC 和编码器的数量以及相应的标识符。 - 这个接口对于初始化显示管道、资源管理和模式设置非常重要。
- 用户空间程序可以通过执行
DRM_IOCTL_MODE_GETPLANERESOURCES
它用于获取Direct Rendering Manager (DRM)的资源。DRM是Linux内核的一部分,负责处理图形硬件的底层细节。
在使用DRM_IOCTL_MODE_GETPLANERESOURCES时,你需要打开一个DRM设备(例如/dev/dri/card0),然后使用这个ioctl调用来获取资源。这些资源包括帧缓冲区(framebuffers)、CRTC(Cathode Ray Tube Controller)、连接器(connectors)和编码器(encoders)。
这些资源的含义如下:
- 帧缓冲区(Framebuffers):它们包含要显示的像素数据。
- CRTC:CRTC代表整个显示管道,它从一个或多个平面获取像素数据进行混合。
- 连接器(Connectors):在DRM中,连接器是显示接收器的一般抽象,包括固定面板或任何其他可以以某种形式显示像素的设备。
- 编码器(Encoders):编码器从CRTC获取像素数据,并将其转换为任何连接的连接器可以接受的格式。
请注意,这些资源的数量可能会根据你的硬件配置和当前的显示设置而变化。在使用这些资源之前,你可能需要检查它们的可用性和状态。。
DRM_IOCTL_MODE_GETCRTC
是一种用于获取有关给定 CRTC(Cathode Ray Tube Controller)的信息的 IOCTL(Input/Output Control)命令。详情如下:
- CRTC 是什么?
- CRTC 是显示控制器,负责将图形数据发送到显示设备(例如显示器或电视)。
- 它管理像素时钟、扫描线和帧缓冲区的刷新。
- DRM_IOCTL_MODE_GETCRTC 的作用
- 通过调用
DRM_IOCTL_MODE_GETCRTC,应用程序可以获取有关特定 CRTC 的信息。 - 这些信息可能包括 CRTC 的当前模式、分辨率、刷新率等。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_GETCRTC,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETOUTPUT:获取有关特定输出的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_MODE_SETCRTC
用于在 Linux 内核模式设置(KMS) 中设置特定 CRTC(Cathode Ray Tube Controller) 的参数。详情如下:
- CRTC 是什么?
- CRTC 是显示控制器,负责将图形数据发送到显示设备(例如显示器或电视)。
- 它管理像素时钟、扫描线和帧缓冲区的刷新。
- DRM_IOCTL_MODE_SETCRTC 的作用
- 通过调用
DRM_IOCTL_MODE_SETCRTC,应用程序可以设置特定 CRTC 的参数,例如分辨率、刷新率等。 - 这对于配置显示输出非常重要。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_SETCRTC,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_MODE_GETPLANE
用于从 Linux 内核模式设置(KMS) 中获取特定 平面(Plane) 的信息。详情如下:
- DRM_IOCTL_MODE_GETPLANE 的作用
- 通过调用
DRM_IOCTL_MODE_GETPLANE,应用程序可以获取有关特定平面的信息。 - 这些信息可能包括平面的当前状态、位置、大小、像素格式等。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_GETPLANE,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_MODE_SETPLANE
用于在 Linux 内核模式设置(KMS) 中设置特定 平面(Plane) 的参数。详情如下:
- DRM_IOCTL_MODE_SETPLANE 的作用
- 通过调用
DRM_IOCTL_MODE_SETPLANE,应用程序可以设置特定平面的参数,例如分辨率、刷新率等。 - 这对于配置显示输出非常重要。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_SETPLANE,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
Cursor
DRM_IOCTL_MODE_CURSOR
用于操作特定 CRTC(Cathode Ray Tube Controller) 的 光标平面(Cursor Plane)。详情如下:
- CRTC 是什么?
- CRTC 是显示控制器,负责将图形数据发送到显示设备(例如显示器或电视)。
- 它管理像素时钟、扫描线和帧缓冲区的刷新。
- 光标平面(Cursor Plane)的作用
- 光标平面 是一种特殊的显示平面,用于显示光标或其他小型图形元素。
- 通过调用
DRM_IOCTL_MODE_CURSOR,应用程序可以操作光标平面,例如设置光标的位置、大小、图像等。
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_CURSOR,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_MODE_CURSOR2
用于操作特定 CRTC(Cathode Ray Tube Controller) 的 光标平面(Cursor Plane)⁵。详情如下:
- CRTC 是什么?
- CRTC 是显示控制器,负责将图形数据发送到显示设备(例如显示器或电视)。
- 它管理像素时钟、扫描线和帧缓冲区的刷新。
- 光标平面(Cursor Plane)的作用
- 光标平面 是一种特殊的显示平面,用于显示光标或其他小型图形元素。
- 通过调用
DRM_IOCTL_MODE_CURSOR2,应用程序可以操作光标平面,例如设置光标的位置、大小、图像等。
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_CURSOR2,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
区别
DRM_IOCTL_MODE_CURSOR 和 DRM_IOCTL_MODE_CURSOR2 都是 IOCTL(Input/Output Control)命令,用于操作特定 CRTC(Cathode Ray Tube Controller) 的 光标平面(Cursor Plane)。它们之间的区别如下:
- DRM_IOCTL_MODE_CURSOR
DRM_IOCTL_MODE_CURSOR是旧版本的命令,用于设置光标平面的参数,例如光标的位置、大小、图像等。- 它遵循旧的光标平面操作语义。
- DRM_IOCTL_MODE_CURSOR2
DRM_IOCTL_MODE_CURSOR2是新版本的命令,用于相同的目的,但可能具有更丰富的功能。- 它可能支持更多属性,例如更灵活的光标形状、透明度等。
总之,DRM_IOCTL_MODE_CURSOR2 可能是对 DRM_IOCTL_MODE_CURSOR 的改进或扩展,以提供更好的光标平面控制。
Sync Obj
DRM_IOCTL_SYNCOBJ_CREATE
用于在 Linux 内核模式设置(KMS) 中创建 同步对象(Sync Object)。详情如下:
- 同步对象是什么?
- 同步对象 是一种用于协调多个并发任务之间的同步机制。
- 在图形渲染中,同步对象通常用于确保不同图形操作的执行顺序或避免竞态条件。
- DRM_IOCTL_SYNCOBJ_CREATE 的作用
- 通过调用
DRM_IOCTL_SYNCOBJ_CREATE,应用程序可以创建一个同步对象。 - 同步对象可以用于跟踪图形操作的完成状态,例如等待渲染完成或等待其他事件。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_SYNCOBJ_CREATE,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_SYNCOBJ_HANDLE_TO_FD
用于在 Linux 内核模式设置(KMS) 中将特定 同步对象(Sync Object) 的句柄转换为文件描述符(File Descriptor)。
详情如下:
- 同步对象是什么?
- 同步对象 是一种用于协调多个并发任务之间的同步机制。
- 在图形渲染中,同步对象通常用于确保不同图形操作的执行顺序或避免竞态条件。
- DRM_IOCTL_SYNCOBJ_HANDLE_TO_FD 的作用
- 通过调用
DRM_IOCTL_SYNCOBJ_HANDLE_TO_FD,应用程序可以将同步对象的句柄转换为文件描述符。 - 文件描述符是一种用于在进程之间传递句柄的机制。这些文件描述符是不透明的,只能用于传递同步对象句柄。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_SYNCOBJ_HANDLE_TO_FD,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_SYNCOBJ_SIGNAL
用于在 Linux 内核模式设置(KMS) 中直接触发特定 同步对象(Sync Object)。这个命令提供了一种用户空间手动触发同步对象的机制。
以下是关于 DRM_IOCTL_SYNCOBJ_SIGNAL 的一些要点:
- 同步对象是什么?
- 同步对象 是一种用于协调多个并发任务之间的同步机制。
- 在图形渲染中,同步对象通常用于确保不同图形操作的执行顺序或避免竞态条件。
- DRM_IOCTL_SYNCOBJ_SIGNAL 的作用
- 通过调用
DRM_IOCTL_SYNCOBJ_SIGNAL,用户空间可以直接触发特定同步对象。 - 这对于手动触发同步对象非常有用。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_SYNCOBJ_SIGNAL,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
Lease
DRM_IOCTL_MODE_CREATE_LEASE
用于在 Linux 内核模式设置(KMS) 中创建 租约(Lease)。详情如下:
- 租约是什么?
- 租约 是一种机制,用于管理图形资源的共享和访问权限。
- 在多个图形客户端之间,租约允许控制对特定资源(例如帧缓冲区、平面、连接器等)的访问。
- DRM_IOCTL_MODE_CREATE_LEASE 的作用
- 通过调用
DRM_IOCTL_MODE_CREATE_LEASE,应用程序可以创建一个租约。 - 租约可以用于协调多个图形客户端之间的资源共享,以确保资源的正确使用和访问权限。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_CREATE_LEASE,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_MODE_LIST_LESSEES
用于从 Linux 内核模式设置(KMS) 中获取特定 租约(Lease) 所有租户(lessees)的标识符(identifiers)。
以下是关于 DRM_IOCTL_MODE_LIST_LESSEES 的一些要点:
- 租约是什么?
- 租约 是一种机制,用于管理图形资源的共享和访问权限。
- 在多个图形客户端之间,租约允许控制对特定资源(例如帧缓冲区、平面、连接器等)的访问。
- DRM_IOCTL_MODE_LIST_LESSEES 的作用
- 通过调用
DRM_IOCTL_MODE_LIST_LESSEES,应用程序可以获取特定租约的所有租户的标识符。 - 这对于了解租约的使用情况以及资源共享非常有用。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_LIST_LESSEES,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_GETCRTC:获取有关特定 CRTC 的信息。DRM_IOCTL_MODE_SETCRTC:设置 CRTC 参数。DRM_IOCTL_MODE_ADDFB:添加新的帧缓冲区对象。DRM_IOCTL_MODE_RMFB:移除帧缓冲区对象。
- 除了
DRM_IOCTL_MODE_GET_LEASE
用于从 Linux 内核模式设置(KMS) 中获取特定 租约(Lease) 的信息。详情如下:
- 租约是什么?
- 租约 是一种机制,用于管理图形资源的共享和访问权限。
- 在多个图形客户端之间,租约允许控制对特定资源(例如帧缓冲区、平面、连接器等)的访问。
- DRM_IOCTL_MODE_GET_LEASE 的作用
- 通过调用
DRM_IOCTL_MODE_GET_LEASE,应用程序可以获取有关特定租约的信息。 - 这些信息可能包括租约的状态、租约的资源列表、租约的持有者等。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_GET_LEASE,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_CREATE_LEASE:创建租约。DRM_IOCTL_MODE_LIST_LESSEES:列出租约的所有租户。
- 除了
DRM_IOCTL_MODE_REVOKE_LEASE
用于在 Linux 内核模式设置(KMS) 中撤销特定 租约(Lease) 的权限。
以下是关于 DRM_IOCTL_MODE_REVOKE_LEASE 的一些要点:
- 租约是什么?
- 租约 是一种机制,用于管理图形资源的共享和访问权限。
- 在多个图形客户端之间,租约允许控制对特定资源(例如帧缓冲区、平面、连接器等)的访问。
- DRM_IOCTL_MODE_REVOKE_LEASE 的作用
- 通过调用
DRM_IOCTL_MODE_REVOKE_LEASE,应用程序可以撤销特定租约的权限。 - 这对于限制资源的访问或更改租约的状态非常有用。
- 通过调用
- 其他 DRM IOCTL 命令
- 除了
DRM_IOCTL_MODE_REVOKE_LEASE,还有其他与显示设置相关的 IOCTL 命令,例如:DRM_IOCTL_MODE_CREATE_LEASE:创建租约。DRM_IOCTL_MODE_LIST_LESSEES:列出租约的所有租户。
- 除了