进程内存检查
1.进程内存映射文件smaps
在内核的数据结构中,进程、进程使用内存、虚拟内存块和一个二进制程序文件的对应关系图如下。
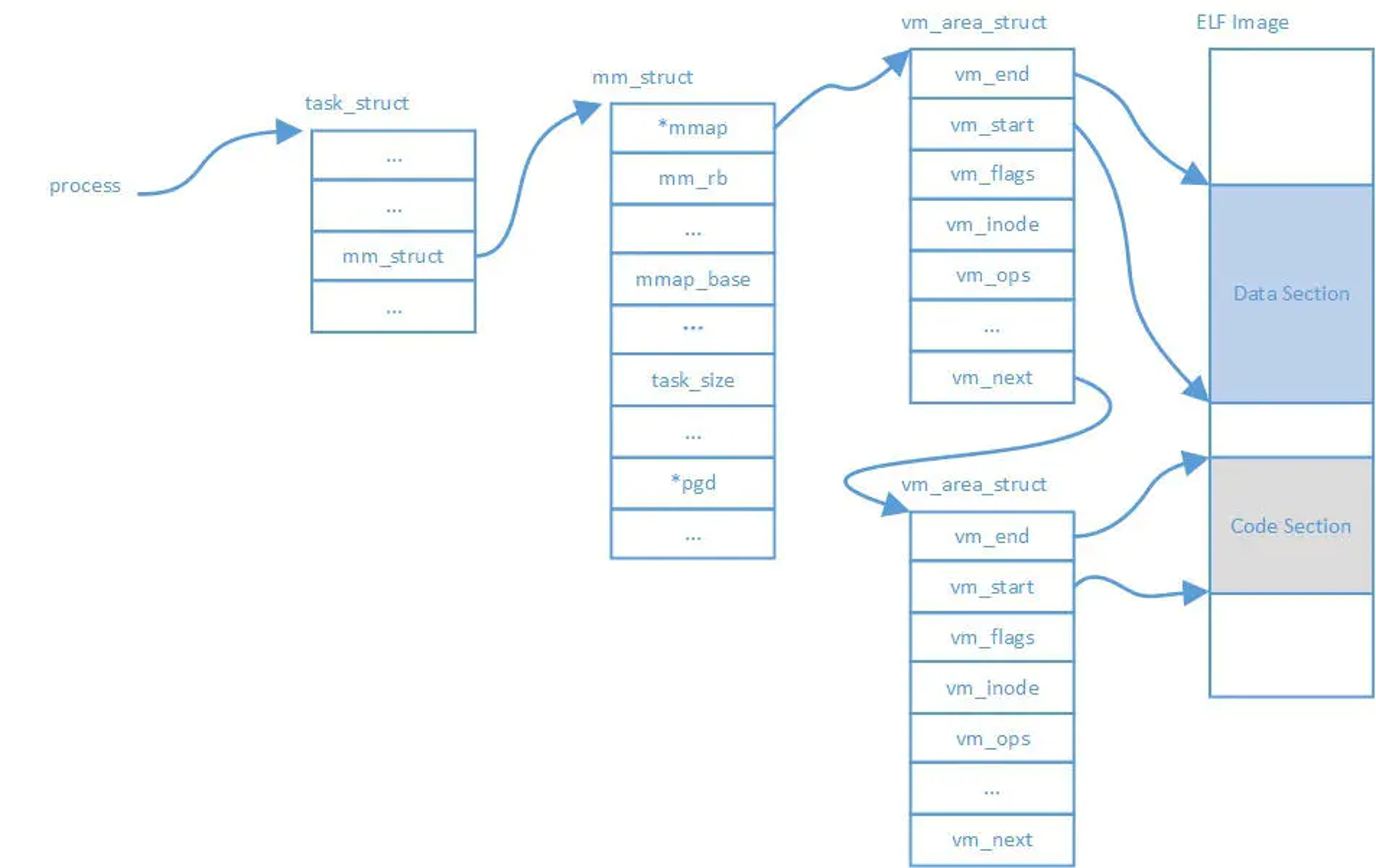
查看/proc/${PID}/smaps,可以得到每一个vm_area_node的详细信息。
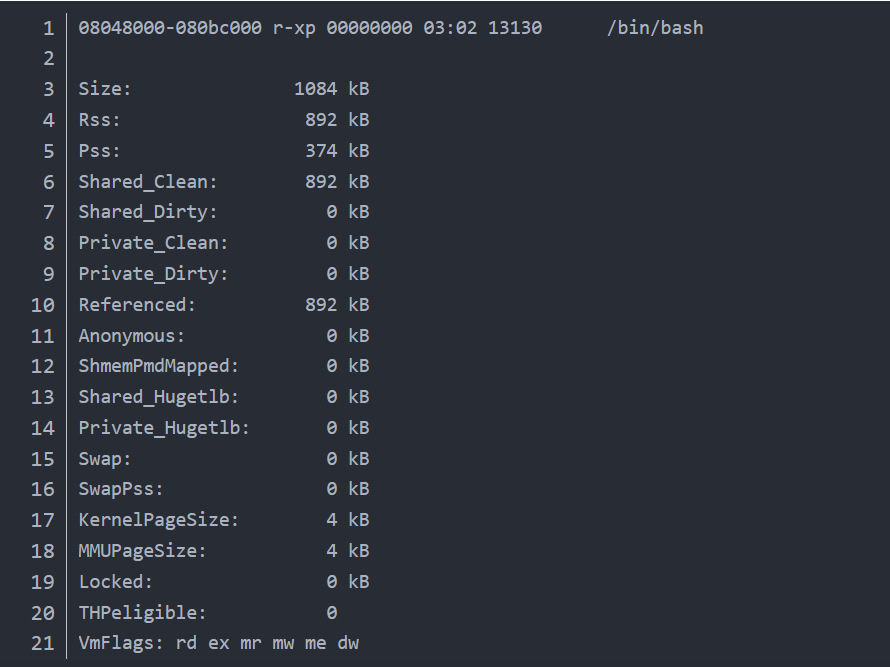
下图是一个具体的vm_area_node信息。
1.1 两种映射
下面两种映射的介绍,是为了下一节解释各字段含义做准备。
- 文件映射
就是存储介质(比如:磁盘)中的数据通过文件系统映射到内存再通过文件映射映射到虚拟空间,这样,用户就可以在用户空间通过 open, read, write 等函数区操作文件内容。代码中函数open(), read(), write(), close(), mmap(fd,…)… 操作的虚拟地址都属于文件映射。
- 匿名映射
就是用户空间要求内核分配一定的物理内存来存储数据,这部分内存不属于任何文件。内核就使用匿名映射将内存中的某段物理地址与用户空间一一映射,这样用户就可用直接操作虚拟地址来范围这段物理内存。比如使用malloc(), mmap(NULL,…)申请内存。
1.2 各字段含义
- 第一行

- 08048000-080bc000: 该虚拟内存段的开始和结束位置
- r-xp:内存段的权限,分别是可读、可写、可运行、私有或共享,最后一位p代表私有,s代表共享(如共享的内存, shm). 如果有”w”,表示是库的数据区.
- 00000000: 虚拟内存段起始地址在对应的映射文件中以页为单位的偏移量, 对匿名映射,它等于0或者vm_start/PAGE_SIZE
- 03:02: 文件的主设备号和次设备号。 对有名映射来说,是映射的文件所在设备的设备号 对匿名映射来说,因为没有文件在磁盘上,所以没有设备号,始终为00:00。
- 13130: 被映射到虚拟内存的文件的索引节点号,通过该节点可以找到对应的文件, 对匿名映射来说,因为没有文件在磁盘上,所以为0
- /bin/bash: 被映射到虚拟内存的文件名称。后面带(deleted)的是内存数据,可以被销毁。 对有名映射来说,是映射的文件名。 对匿名映射来说,是此段虚拟内存在进程中的角色。[stack]表示在进程中作为栈使用,[heap]表示堆。其余情况比如mmap(NULL, ….)则无显示。
-
Size
虚拟内存空间大小。但是这个内存值不一定是物理内存实际分配的大小,因为在用户态上,虚拟内存总是延迟分配的。这个值计算也非常简单,就是该VMA的开 始位置减结束位置。
延迟分配:就是当进程申请内存的时候,Linux会给他先分配页,但是并不会区建立页与页框的映射关系,也就是并不会分配物理内存,而当真正使用的时候,就会产生一个缺页异常,硬件跳转page fault处理程序执行,在其中分配物理内存,然后修改页表(创建页表项)。异常处理完毕,返回程序用户态,继续执行。
-
Rss resident set size
实际分配的内存,这部分物理内存已经分配,不需要缺页中断就可以使用的。但可能是和其他进程共享的。
这里有一个公式计算Rss:
Rss=Shared_Clean+Shared_Dirty+Private_Clean+Private_Dirty -
Shared_Clean Shared_Dirty Private_Clean Private_Dirty
share/private:表示该页面是共享还是私有。
dirty/clean: 表示该页面是否被修改过,如果修改过(dirty),在页面被淘汰的时候,就会把该脏页面回写到交换分区(换出,swap out)。有 一个标志位用于表示页面是否dirty。
share/private_dirty/clean 计算逻辑:
查看该page的引用数,如果引用>1,则归为shared,如果是1,则归为private,再查看该page的flag,是否标记为_PAGE_DIRTY,如果不是,则认为干净的
-
Pss proportional set size
平摊计算后的实际物理使用内存(有些内存会和其他进程共享,例如mmap进来的)。实际上包含上面private_clean+private_dirty,和按比例均分的shared_clean、shared_dirty。
举个计算Pss的例子:
如果进程A有x个private_clean页面,有y个private_dirty页面,有z个shared_clean仅和进程B共享,有h个shared_dirty页面和进程B、C共享。那么进程A的Pss为:x + y + z/2 + h/3
-
Referenced
当前页面被标记为已引用或者包含匿名映射(The amount of memory currently marked as referenced or a mapping associated with a file may contain anonymous pages)。在Linux内存管理的页面替换算法中,当某个页面被访问后,Referenced标志被设置,如果该标志设置了,就不能将该页移出。
-
Anonymous
匿名映射的物理内存,这部分内存不是来自于文件。
-
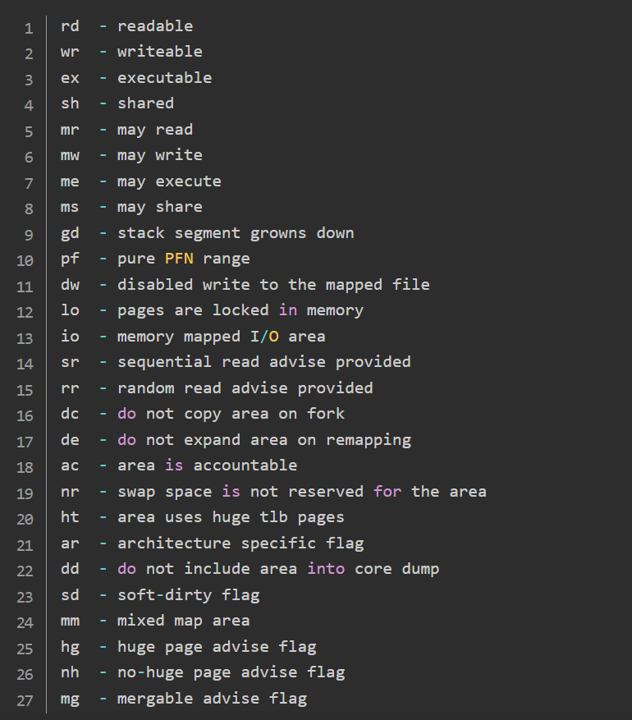
VmFlags
vm_area的各种属性,具体如下:
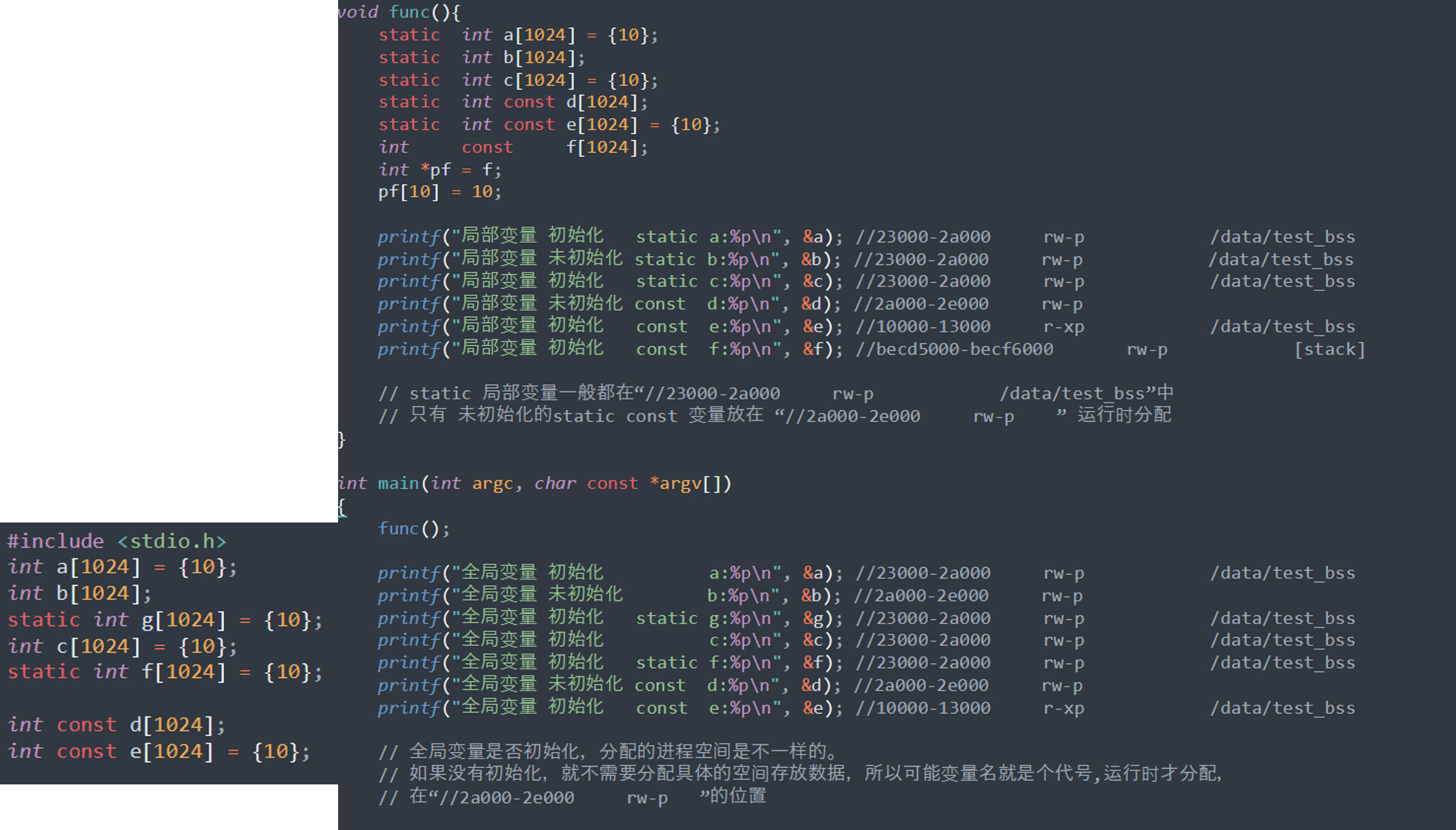
1.3 不同变量的位置
一个库映射到内存, 一般分为代码段、数据段和只读数据段
- r- --p: so中的字符串常数
- rw--p: so中的全局变量,静态变量
- r- -xp: so的代码段,常量
- - ---p: 表示该 VMA 是私有的,不可执行,且不可读写. 这通常用于保护敏感数据或代码,防止其被修改或执行
下面这段代码展示了不同变量的存储位置:
2.free 命令
free 命令用于显示系统的内存状态,包括物理内存、交换内存(swap)和内核缓冲区内存。详细输出如下:

- Mem 行(第二行)显示了内存的使用情况。
-
Swap行(第三行)显示了交换空间的使用情况。
- total: 表示系统总的可用物理内存和交换空间大小。
- used : 表示已经被使用的物理内存和交换空间。
- free : 表示还有多少物理内存和交换空间可用使用。
- shared: 显示被共享使用的物理内存大小。
- buff/cache: 显示被 buffer 和 cache 使用的物理内存大小。
- available: 显示还可以被应用程序使用的物理内存大小。
2.1 buffer与cache
-
buffer: 缓冲区
CPU 在进行一系列操作时,先在内存的一块区域进行,一系列操作完成后,再一次性把该内存区域提交给外部设备,来对这个区域操作。
比如写一堆数据给硬盘,就先写到内存的一块区域,写好后一次写回到硬盘。又比如读数据,先在内存划出一块区域,让硬盘控制器写数据到这块区域,写好后,CPU 直接访问该区域得到数据。这个内存区域就叫buffer
缓冲区是内存或存储的一部分,用于在等待从输入设备传输到输出设备时存放项目。
操作系统通常在打印文档时使用缓冲区。这个过程称为排队(spooling),它将要打印的文档发送到缓冲区,而不是立即发送到打印机。如果打印机没有自己的内部存储器,或者内存已满,操作系统的缓冲区会保存等待打印的信息,同时打印机以自己的速度从缓冲区打印。
通过将文档排队到缓冲区,处理器可以继续解释和执行指令,同时打印机进行打印。这使用户可以在打印机打印时继续在计算机上进行其他任务。多个打印作业在缓冲区中排队(发音为“Q”)。一个名为打印排队程序(print spooler)的程序拦截操作系统中要打印的文档,并将其放入队列中
-
cache:缓存
CPU 要访问一块数据时,首先访问内存的某个区域,看是否有该数据的缓存,有则直接访问,没有则访问它的来源地。 CPU 利用内存或高速缓存对数据的再备份,为以后的再次访问提供方便
缓存如今的大多数计算机通过缓存(发音为“cash”)来提高处理速度。
缓存有两种主要类型:内存缓存和磁盘缓存。让我们详细了解一下内存缓存。
L1 缓存:
L1 缓存直接内置在处理器芯片中。
它通常容量很小,范围从 8 KB 到 128 KB。 L1 缓存存储经常使用的指令和数据,以便快速访问。L2 缓存:
L2 缓存比 L1 缓存稍慢,但容量更大。 它的大小范围从 64 KB 到 16 MB。 一些现代处理器包括高级传输缓存,这是一种直接内置在处理器芯片上的 L2 缓存类型。 使用高级传输缓存的处理器的性能比不使用它的处理器要快得多。 现今的个人计算机通常具有 512 KB 到 12 MB 的高级传输缓存。
缓存通过存储经常使用的指令和数据来显著加快处理时间。
当处理器需要一条指令或数据时,它按照以下顺序搜索内存:L1 缓存,然后是 L2 缓存,然后是 RAM。
如果所需信息在内存中找不到,处理器必须搜索速度较慢的存储介质,例如硬盘或光盘。
2.2. 手动释放缓存
- 首先,使用sync命令将未写入磁盘的数据同步到磁盘,以确保文件系统的完整性。
- 然后,通过设置/proc/sys/vm/drop_caches来释放内存缓存:
- echo 1 > /proc/sys/vm/drop_caches:释放页缓存。
- echo 2 > /proc/sys/vm/drop_caches:释放 dentries 和 inodes。
- echo 3 > /proc/sys/vm/drop_caches:释放所有缓存。
3.mtrace
mtrace 是 Linux 系统内核自带的一个内存追踪函数。它会在每个内存申请函数(malloc、realloc、calloc)的位置记录下信息,并在每个内存释放的位置记录下 free 的内存信息。其中包含有内存申请的地址、内存申请的大小、释放内存的地址、释放内存的大小。
具体来说,mtrace 函数的作用如下:
- 安装钩子函数,用于跟踪内存分配和释放。
- 记录有关内存分配和释放的跟踪信息。
- 可以用于发现程序中的内存泄漏和试图释放未分配内存的情况。
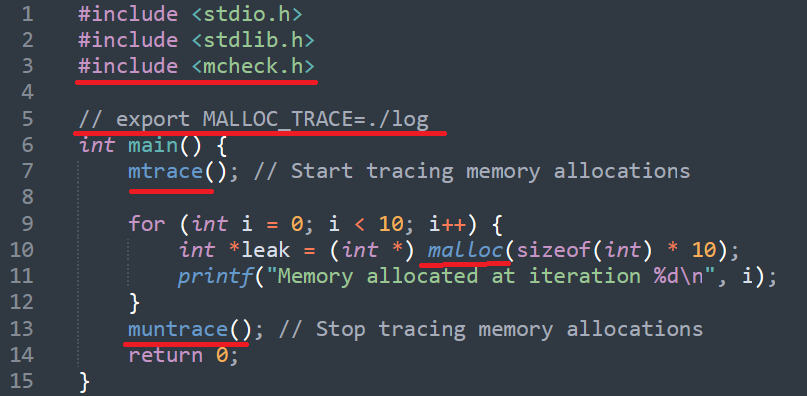
使用方式:
- 在代码中包含 <mcheck.h> 头文件。
- 在程序启动时调用 mtrace() 函数,开启内存分配和释放跟踪。
- 程序结束时,可以调用 muntrace() 函数关闭内存分配和释放跟踪。
- 运行mtrace脚本,分析跟踪日志,生成报告。
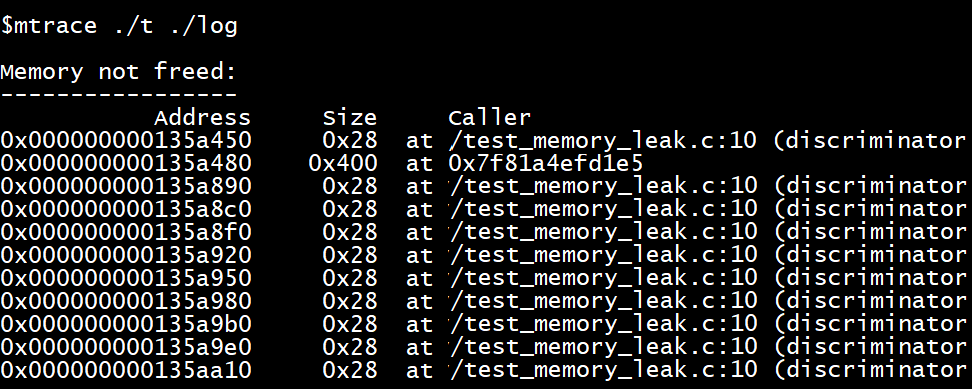
请注意,mtrace 的跟踪输出通常是文本形式,不一定易于人类阅读。GNU C 库提供了一个 Perl 脚本 mtrace,用于解析跟踪日志并生成人类可读的输出。为了获得最佳效果,建议编译时启用调试,以便在可执行文件中记录行号信息。不过,mtrace 的跟踪会带来性能损耗.如果 MALLOC_TRACE 没有指向有效且可写的路径, 则mtrace不会记录信息。
4.strace与ltrace
ltrace 用于跟踪程序的库函数调用,而 strace 则用于跟踪系统调用。 它们都基于 ptrace 系统调用,但跟踪库函数和跟踪系统调用之间存在差异。 通过它们,我们也可以对应用的内存申请、释放进行跟踪。
ltrace 的工作原理:
- ptrace 附加到正在运行的程序。
- 定位程序的 PLT。
- 使用 PTRACE_POKETEXT 设置软件断点(int $3 指令)覆盖库函数的 PLT 中的汇编 trampoline。
- 恢复程序执行。
strace 应该也是相类似的工作原理
4.1 strace
strace 是一个强大的 Linux 命令,用于诊断、调试和统计。它允许您跟踪正在运行的程序的系统调用和接收的信号。下面是一些关于 strace 的参数使用方法。
- -c:统计每个系统调用的执行时间、次数和错误次数。 示例:打印执行 uptime 时系统调用的时间、次数和错误次数:
strace -c uptime - -f:跟踪子进程,这些子进程是由当前跟踪的进程创建的。
- -i:在系统调用时打印指令指针。
- -t:跟踪的每一行都以时间为前缀。
- -tt:如果给出两次,则打印时间将包括微秒。
- -ttt:如果给定三次,则打印时间将包括微秒,并且前导部分将打印为自启动以来的秒数。
- -T:显示花费在系统调用上的时间。
限定表达式:
- -e trace=set:仅跟踪指定的系统调用集。例如,trace=open,close,read,write 表示仅跟踪这四个系统调用。
- -e trace=file:跟踪所有以文件名作为参数的系统调用。示例:打印执行 ls 时与文件有关的系统调用:
strace -e trace=file ls - -e trace=process:跟踪涉及进程管理的所有系统调用。
- -e trace=network:跟踪所有与网络相关的系统调用。
- -e trace=signal:跟踪所有与信号相关的系统调用。
- -e trace=ipc:跟踪所有与 IPC 相关的系统调用。
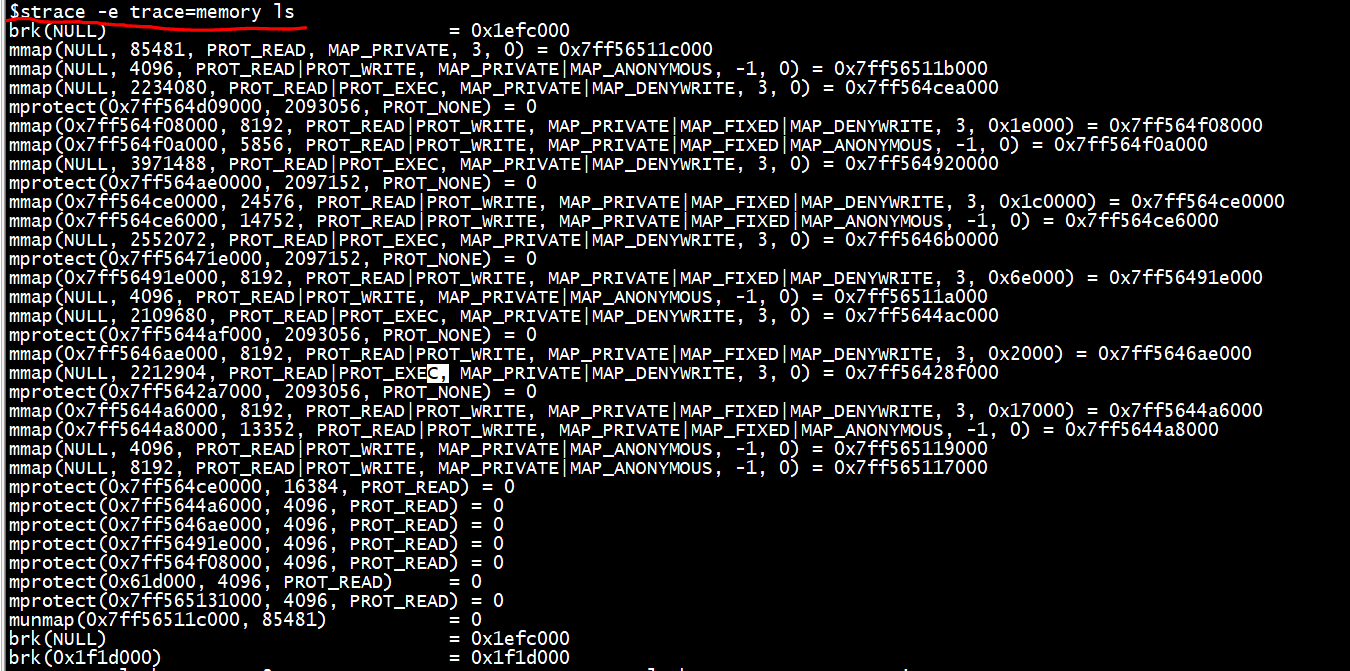
- -e trace=memory:跟踪所有与 momory 相关的系统调用。
其他参数:
- -o 文件名:将跟踪输出写入文件而不是 stderr。
- -p pid:使用进程 ID pid 附加到该进程并开始跟踪
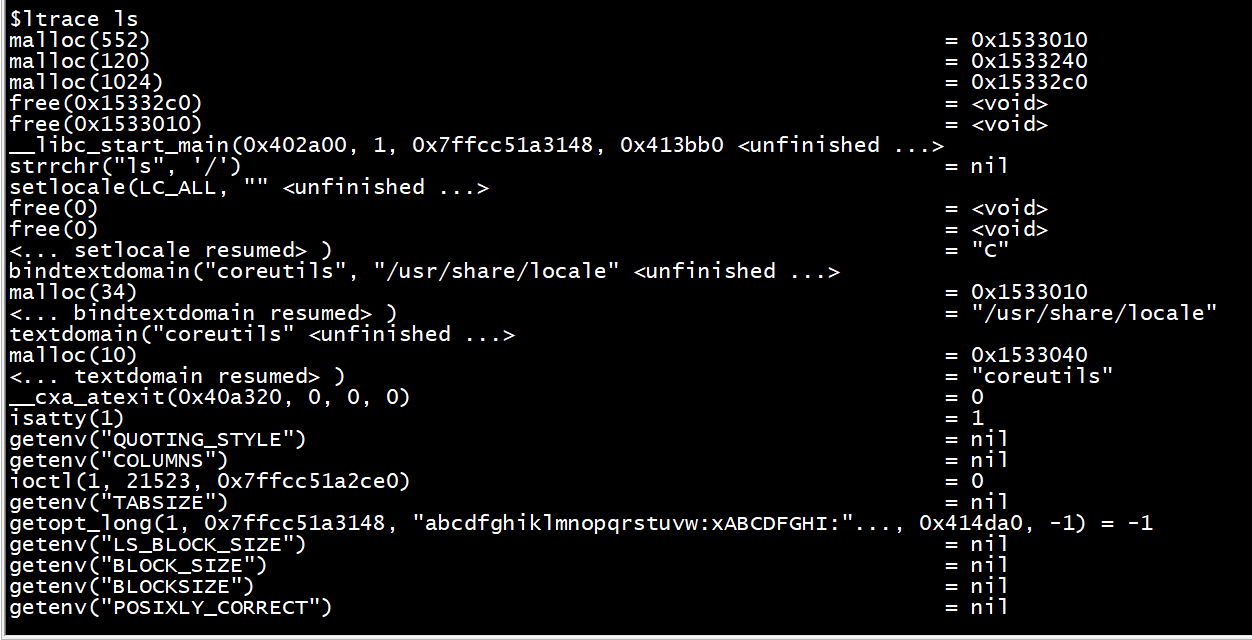
下面是运行 strace ls 的输出
4.2 ltrace
ltrace 是一个用于跟踪程序库调用的 Linux 工具。它可以拦截并记录被执行进程调用的动态库函数,以及该进程接收到的信号。此外,ltrace 还可以拦截并打印程序执行的系统调用。
常用参数和示例: -c:统计每个系统调用的执行时间、次数和错误次数。 示例:打印执行 uptime 时系统调用的时间、次数和错误次数:
ltrace -c uptime
- -f:跟踪子进程,这些子进程是由当前跟踪的进程创建的。
- -i:在系统调用时打印指令指针。
- -t:跟踪的每一行都以时间为前缀。
- -tt:如果给出两次,则打印时间将包括微秒。
- -ttt:如果给定三次,则打印时间将包括微秒,并且前导部分将打印为自启动以来的秒数。
- -T:显示花费在系统调用上的时间。
限定表达式:
- -e trace=set:仅跟踪指定的系统调用集。例如,trace=open,close,read,write 表示仅跟踪这四个系统调用。
- -e trace=file:跟踪所有以文件名作为参数的系统调用。示例:打印执行 ls 时与文件有关的系统调用:
ltrace -e trace=file ls - -e trace=process:跟踪涉及进程管理的所有系统调用。
- -e trace=network:跟踪所有与网络相关的系统调用。
- -e trace=signal:跟踪所有与信号相关的系统调用。
- -e trace=ipc:跟踪所有与 IPC 相关的系统调用。
其他参数:
- -o 文件名:将跟踪输出写入文件而不是 stderr。
- -p pid:使用进程 ID pid 附加到该进程并开始跟踪。
下面是运行 ltrace ls 的输出